
WHEN ARCHITECTURE FAILS
ENFORCING COHERENCE IN THE DAY AND AGE OF DATA AND AI


When Architecture Fails: Enforcing Coherence in the Age of Data and AI
Data & AI Cognitive Architecture: A Federated Model
By Mustafa Qizilbash
Monograph Structure Overview
Structural Failure of Enterprise Data Architecture: Why modern data architectures lose coherence as they scale.
Foundations of Federated Enterprise Architecture: How federation separates ownership from control to sustain alignment.
DAC Architectural Topology: The structural model that enforces how data enters, moves, and is consumed.
The Integration Hub: Structural Control of Ingestion: A single, governed entry point that eliminates ingestion-driven divergence.
Enterprise and Business Zones: Federated Ownership Model: How domain autonomy is balanced with enterprise-wide structural control.
Virtualization Layer: Unified Serving Plane: A controlled access layer that standardizes consumption and prevents fragmentation.
Absorbing AI Within Federation: How AI operates within architectural boundaries without creating parallel systems.
Governance Blueprint and Enforcement: Governance embedded as structure, not policy or coordination.
Operational and Economic Implications: How structural control enforces accountability, efficiency, and cost discipline.
DAC Adoption and Architectural Doctrine: How to transition from fragmented systems to enforced architectural coherence.
Monograph Flow Categorization
1–3 → Structural breakdown of modern enterprise data architecture
4–6 → Foundational model for federated coherence
7–10 → Enforcement mechanisms within DAC architecture
11 → Appendix
1. Structural Failure of Enterprise Data Architecture
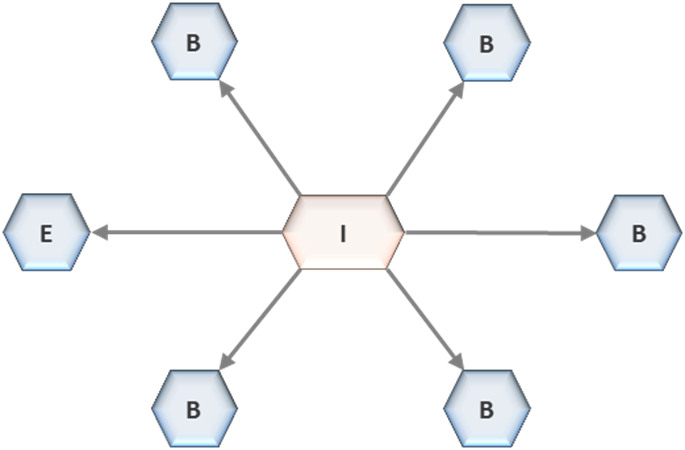
Enterprise data architecture is failing. Not because organizations lack investment, or because the problem is inherently too complex, but because the structure required to hold these ecosystems together is either weak or absent. As data landscapes stretch across domains, platforms, and workloads, coherence simply does not sustain itself. Below diagram show the potentiate challenges faced by different persona(s) in an organization.
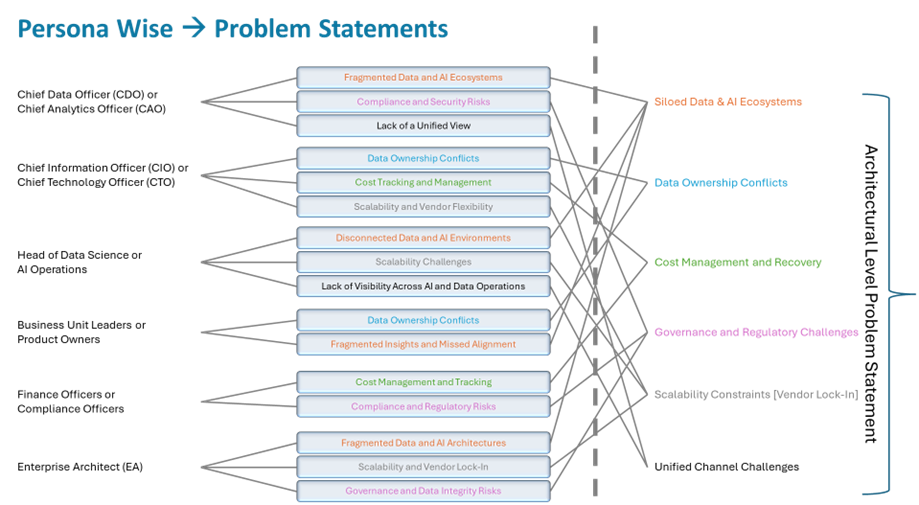
Over the past decade, there has been no shortage of progress. Cloud-native platforms, lakehouse patterns, distributed processing, governance tooling - none of this is immature anymore. And yet the outcomes tell a different story. Environments expand, but alignment erodes. Governance becomes more visible, more documented, more discussed - but less effective in practice. Analytical capability grows, but trust lags behind, sometimes significantly. These are not isolated execution failures. They point to something more fundamental.
Most architectures are built to enable. They focus on access, flexibility, integration. What they don’t do - at least not in any enforceable way - is constrain behavior. How data enters the system varies. How it moves across domains is often negotiated rather than controlled. Consumption evolves based on local needs, not architectural discipline. Once those boundaries are left open, divergence doesn’t creep in - it’s introduced immediately, at the edges, and then carried forward. You end up with a landscape where each environment operates on its own terms. Ingestion patterns differ. Transformation logic reflects local interpretation. Consumption interfaces evolve independently. What looks like a distributed system is, in reality, a collection of loosely related systems.
Data stops behaving like an enterprise asset and starts behaving like a set of localized artifacts. Definitions drift. Lineage breaks down. Governance, at that point, becomes observational - it reports on divergence rather than preventing it.
None of the dominant architectural models have fully resolved this. Centralized approaches maintain control, but at the cost of adaptability. They struggle when distribution becomes a requirement rather than an exception. Decentralized models swing in the opposite direction - ownership is distributed, flexibility increases, but discipline fades and divergence accumulates quickly. Federated models attempt to balance the two, but in practice they depend on alignment and shared standards that are rarely enforced. Without hard boundaries, federation tends to erode over time into decentralization. The pattern underneath all of this is consistent. Architecture defines intent. It does not ensure adherence. Principles, patterns, and policies assume coordination across teams. At small scale, that might hold. At enterprise scale, it doesn’t.
Fragmentation starts early - at ingestion. Multiple pipelines are built to the same source systems, each slightly different. Extraction logic varies. Refresh cycles don’t align. Even interpretation of the same source data begins to diverge. That variation isn’t corrected - it propagates. From there, it compounds. Data is replicated across platforms to serve different workloads. Each environment reshapes it according to its own objectives. Over time, transformation logic drifts. Metadata becomes inconsistent, sometimes incomplete. Lineage exists in fragments, if at all. What you’re left with is not a shared foundation, but a series of parallel interpretations. As the system grows, so does the problem. Every additional pipeline, every replication point, every transformation layer introduces more divergence. There is no natural mechanism that pulls the system back toward alignment.
Capability increases. Structural integrity weakens.
At some point, the symptoms become hard to ignore. Core business entities - customers, products, transactions - start appearing in multiple forms that don’t reconcile cleanly. Alignment is no longer a design property; it becomes an operational burden. Teams coordinate, negotiate, and manually reconcile, often under time pressure. The absence of an authoritative dataset isn’t accidental - it reflects a lack of structural control upstream. Operationally, the impact is immediate. Ingestion inconsistencies lead to different data states across environments. Independent transformations produce outputs that cannot be directly compared. Metadata gaps obscure lineage, making it difficult to understand how data was derived. Reconciliation becomes routine, not exceptional.
Then AI enters the picture and accelerates everything. AI workloads demand rapid iteration, repeated training, and access to data across domains. When the governed paths can’t keep up, teams build around them. Parallel pipelines appear. Data is copied, reshaped, and used outside existing structures. Those parallel paths don’t stay temporary. They harden. Feature engineering happens in isolation. Training pipelines evolve independently. Over time, what was once a single architecture starts to look like multiple ecosystems, each with its own logic, its own data, its own assumptions.
This has direct consequences for decision-making. The same entity is defined differently depending on where you look. Analytical outputs vary because the underlying data and transformations differ. Consistency becomes situational. Trust becomes conditional. Machine learning systems amplify the problem further. Models inherit the assumptions embedded in their training data. Move them to another environment, and those assumptions don’t always hold. Results shift. Reproducibility breaks down. Without consistent lineage and metadata, it’s difficult to even understand why. Governance doesn’t disappear - but it weakens. Data spans multiple systems, each with its own policies, its own gaps. Visibility fragments. Enforcement becomes partial at best. What remains is coordination - manual, ongoing, and increasingly expensive as the system grows. Cost follows the same pattern. Duplicate pipelines, redundant storage, repeated transformations - they accumulate quietly. Multiple teams pay to maintain variations of the same data. Attribution becomes fuzzy because ownership is obscured by duplication.
These effects reinforce each other. Divergence leads to duplication. Duplication increases inconsistency. Inconsistency reduces trust. Reduced trust drives more localized data creation. The system doesn’t stabilize - it drifts further.
And recovery is not straightforward. Aligning datasets means coordinating across teams with entrenched dependencies and differing interpretations. Transformation logic has to be reconciled, often at the expense of existing workflows. The longer divergence persists, the more expensive it becomes to correct. At a certain point, incremental fixes stop working. Restoring coherence requires structural intervention - redefining pipelines, standardizing transformations, consolidating datasets. These are not small changes. They cut across both operational and analytical layers.
The underlying issue is not scale, or distribution, or even the introduction of AI. It’s the absence of control over how data enters, moves, and is consumed. Policies set expectations, but they don’t enforce behavior. In distributed environments, that distinction matters. If coherence is the goal, control cannot remain optional. It has to be built into the architecture itself. Data entry follows defined validation and standardization rules. Movement across domains is governed, not negotiated. Consumption happens through consistent, controlled interfaces. These are not guidelines - they define how the system operates. This is where Data & AI Cognitive (DAC) Architecture comes in. Not as another variation of existing models, but as a structural correction. It defines control points that are not negotiable. Domains retain autonomy, but only within those boundaries. They don’t decide how data enters, how it moves, or how it is exposed. That is defined once - and enforced

.For a long time, enterprise data architecture has prioritized enablement over control. That trade-off doesn’t hold at scale. Structural control isn’t an enhancement layered on top. It’s the condition required for the architecture to function at all. This didn’t happen overnight. It’s the result of how the industry has responded to scale. Centralized models enforced control but couldn’t keep up with demand. Decentralized approaches restored responsiveness but lost discipline. Federated models tried to bridge the gap, but relied too heavily on coordination. Without hard boundaries, they drifted.
What we see now is the outcome of that progression - capability without constraint. DAC doesn’t introduce a new direction as much as it closes a gap that has been there all along.
2. Foundations of Federated Enterprise Architecture
As enterprise data environments expand across domains, platforms, and workloads, the problem shifts. It is no longer about consolidation. The real issue is whether coordinated operation can be sustained across distributed systems without losing structural integrity. Multiple sources, multiple platforms, multiple domain environments - they all need to coexist. But coexistence without constraint quickly turns into divergence. Centralizing everything into a single platform doesn’t resolve this. It simply collapses under scale and diversity. Something else is required.
Federation addresses that gap. It distributes responsibility, but it does not distribute control indiscriminately. It defines where centralization must remain and where decentralization is acceptable. The distinction matters. Centralization governs structure. Decentralization governs execution. Federation only holds if that boundary is enforced. Without enforcement, it degrades. At the centre of this model is a separation that is often misunderstood - ownership is not the same as governance. Domains own their data, their transformations, their workloads. They execute. But they do not define how data enters the enterprise, how it is classified, or how it is exposed across domains. Those are architectural concerns. If domains take control of them, the structure doesn’t stretch - it dissolves.
That separation forces a more uncomfortable question: what is allowed to vary, and what is not. Domain implementations can and should adapt. Structural rules cannot. Governance here is not advisory, and it is not negotiable. It defines operating conditions. If those conditions can be bypassed through local decisions, they are not governance - they are suggestions. A federated architecture, in practice, is a centralized blueprint with decentralized execution layered on top. The blueprint is not abstract. It defines metadata standards, access control, classification, lifecycle, and the allowed movement of data. These are enforced constraints. Domains operate within them, not around them. What the blueprint does not do is dictate how domains build internally. That remains flexible. It defines interaction, not implementation. Domains can optimize for their own workloads, choose their modeling approaches, structure their transformations as needed - but they cannot alter how data enters the system, how it flows, or how it is exposed.
That boundary is where most implementations fail.
Structural enforcement is not achieved through documentation or alignment sessions. It is achieved through topology. The architecture itself determines how data can move and where control is applied. If movement is unrestricted, autonomy leaks into structural behavior, and fragmentation returns - quietly at first. This is where zones come in. Not as logical groupings or organizational constructs, but as enforcement points. Each zone has a defined role, explicit constraints, and limited operations. Data doesn’t move freely between them. It transitions through controlled paths. Zones introduce order into what would otherwise be an open system. They force data through defined stages. They preserve lineage by design, not by afterthought. They limit replication by constraining where and how data can be copied or transformed. The system becomes predictable - not in what domains do internally, but in how data behaves across the architecture.
Certain controls sit at the core of this structure, and they are not optional.
Ingestion is one of them. If domains are allowed to connect independently to source systems, variation is introduced immediately. Different extraction logic, different refresh cycles, different interpretations. Once that happens, downstream consistency is already compromised. Ingestion defines the initial state of data. If that state is not controlled, nothing downstream will correct it. Movement is another. Data does not move arbitrarily across zones. It follows defined pathways. Those pathways enforce validation, preserve lineage, and constrain transformation. Uncontrolled movement leads to duplication and breaks traceability. At that point, the system cannot explain itself. Exposure follows the same pattern. Domains cannot define their own mechanisms for sharing data externally. Exposure must be mediated through controlled interfaces. Without that, interoperability degrades. Cross-domain usage becomes unreliable - not because the data isn’t there, but because it means different things in different places.
Within these boundaries, domains still have room to operate. They define their models, run their transformations, execute their workloads. But that autonomy is contained. It does not extend into structural behavior. Domains can optimize - but they cannot redefine the system. This is the tension federation manages. Autonomy where variation is acceptable. Control where consistency is required. The architecture draws that line. If it doesn’t, teams will - independently, and inconsistently. Metadata holds the system together. Not as an add-on, but as structure. It defines how data is described, how it is traced, how it is understood across domains. Without consistent metadata, relationships between datasets degrade. Lineage becomes partial. Interpretation becomes ambiguous. The system fragments, even if the topology remains intact.
Cost behaves the same way if left unmanaged. Distributed environments multiply consumption points - pipelines, storage, compute. Without enforced visibility and attribution, duplication grows unchecked. Teams replicate data because they cannot see or trust what already exists. Costs rise, but more importantly, so does inconsistency. Cost control, in this context, is structural. It has to be embedded. Semantic consistency is a different kind of constraint. Domains do not need to implement identical models, but they cannot redefine shared business concepts independently. Where data crosses domains, meaning must remain aligned. Without that, structural control is insufficient. The system may be well-governed technically, but it will still fail operationally.
The strength of federation is not in distributing ownership. That part is easy. It lies in enforcing the conditions that prevent that distribution from turning into fragmentation. Control over entry, movement, and exposure is what stops the system from drifting. Governance is not applied from the outside. It is built into how the system works. Adoption does not happen arbitrarily. There is an order, whether acknowledged or not. Structural control has to come first. Ingestion authority is established before anything else. Data enters through governed pathways, or not at all. Then zonal boundaries are defined - where transformation occurs, where control is applied. Movement between zones is constrained next. Only after these are in place does domain autonomy expand.
Reverse that sequence, and the outcome is predictable. Autonomy fills the gaps. Decentralization takes over. What looks like federation on paper behaves very differently in practice. Skipping steps doesn’t produce a partial federation. It produces a decentralized system with additional overhead.
Federation, when it works, allows distributed environments to scale without losing coherence. It removes reliance on coordination and replaces it with structural enforcement. Domains remain independent in execution, but they do not diverge structurally. The architecture described here builds directly on that premise. Control over how data enters, moves, and is consumed is fixed. Non-negotiable. Domain execution remains flexible, but only within those constraints. That balance is what allows modern workloads - including AI - to operate without breaking consistency, lineage, or governance. Architectures that avoid enforcing these conditions don’t fail immediately. They drift. And once that drift sets in, recovery is expensive. Federation, implemented properly, is not one option among many. At this scale, it is the only model that holds.
3. DAC Architectural Topology
A federated architecture does not operate through principles or governance intent. It requires an explicit topology that determines how data enters the system, how it is organized across domains, and how it is consumed. Without defined and enforced topology, federation cannot sustain coherence. Pipelines proliferate, semantics diverge, and governance becomes reactive rather than controlling. DAC defines this topology through structural boundaries that are enforced across the entire architecture. These boundaries are not conceptual. They determine how data flows, where it is transformed, and how it is accessed. The topology establishes a controlled system in which every data operation occurs within defined constraints

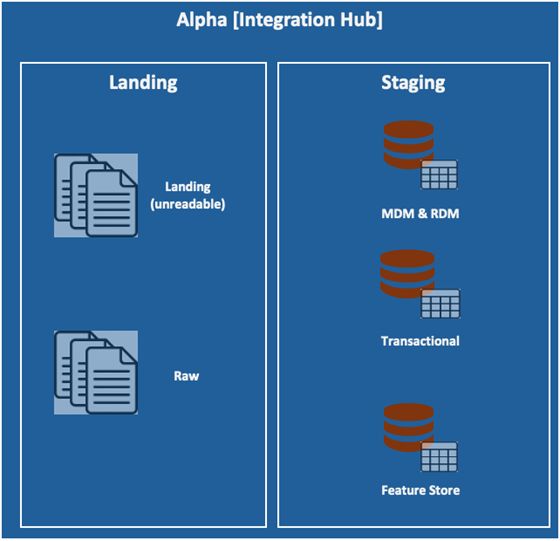
.At the outer edge of the architecture are enterprise source systems. These include operational databases, enterprise applications, and external data providers. They evolve independently and expose heterogeneous integration mechanisms. Allowing analytical environments to connect directly to these systems introduces uncontrolled ingestion pathways. Each connection creates a new pipeline, often duplicating logic, bypassing governance, and introducing variation at the point of entry. Over time, this results in pipeline proliferation and fragmented control. DAC eliminates this condition by enforcing a single ingestion authority: the Integration Hub. All data entering the architecture must pass through this boundary. Direct connections from analytical environments to source systems are not permitted. Each source is integrated once through a governed process, ensuring that ingestion logic is defined, controlled, and consistent. The Integration Hub is not an integration convenience. It is a structural control point. All physical data movement into the architecture is governed through this boundary. Independent pipeline creation outside this control is not allowed. This eliminates variation at the point of entry and establishes a consistent foundation for all downstream operations.
Within the Integration Hub, data progresses through defined layers that enforce traceability and standardization. The landing layer preserves raw data in its original form, ensuring that source-level traceability is maintained. The staging layer applies structural normalization, validation rules, metadata registration, classification, and quality controls. Data that does not meet these conditions is rejected and does not proceed further into the architecture. Entry is conditional, not permissive.
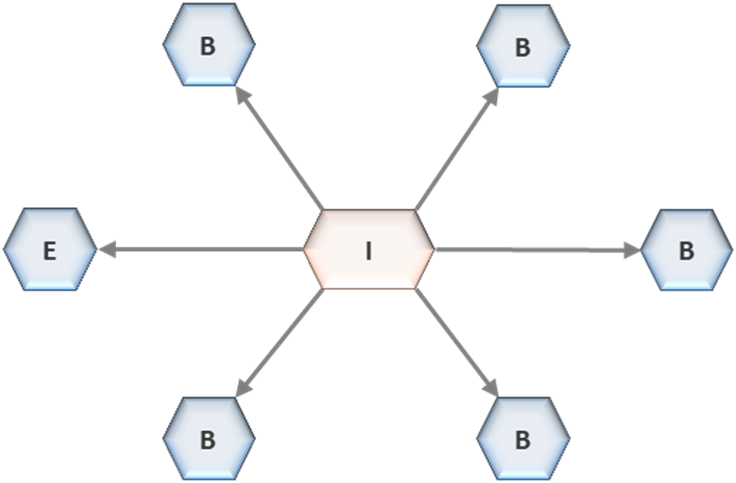
Once ingested and validated, data is made available to analytical environments organized into two structurally distinct zones: the Enterprise Zone and Business Zones. These zones define how data is transformed and consumed within the architecture. They are not independent systems. They are governed environments operating within a shared topology.

The Enterprise Zone provides an integrated analytical environment aligned to shared models and reference data. It supports cross-domain analytics and enterprise-level decision-making. Data within this zone is structured to maintain consistency across domains, ensuring that shared business concepts are aligned and accessible. Business Zones are domain-aligned environments where domains control transformations, models, and performance optimization within architectural constraints. Domains operate independently within these zones, but they do not control structural behavior. Their autonomy is limited to execution within defined boundaries. The relationship between zones is controlled. Direct dependencies between zones are not permitted. Zones cannot extract or replicate datasets through independent pipelines. This restriction prevents uncontrolled data movement and ensures that transformations remain traceable. Zones operate as coordinated environments, not as independent systems exchanging data through unmanaged pathways.
Data consumption and physical data movement are separated within the topology. Cross-domain consumption occurs through the Virtualization Layer, which serves as the unified interface for all analytical access
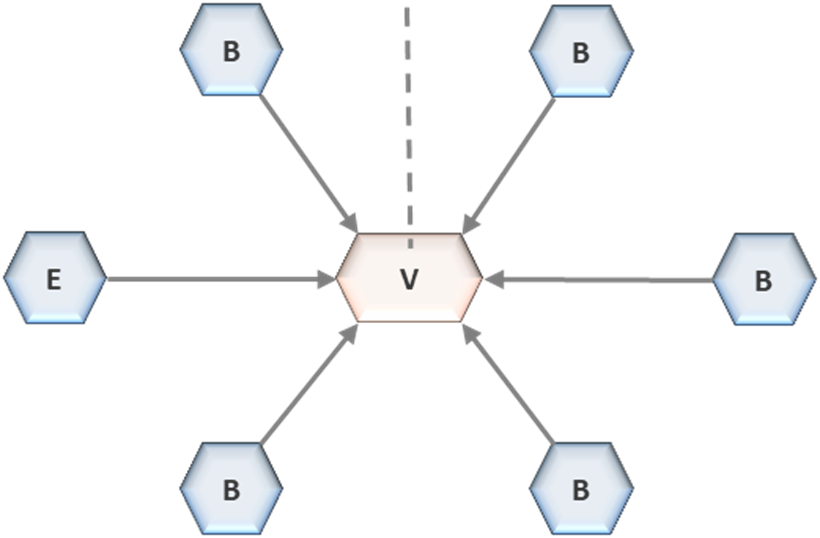
.This layer operates in read-only mode and decouples consumers from underlying storage. Consumers do not access data directly from zones. They access it through controlled interfaces that enforce consistency in how data is interpreted. This separation is structural. Logical access is provided through virtualization, while physical data movement is governed independently. When data must be materialized across zones, it is routed back through controlled pathways rather than being transferred directly. This ensures that lineage is preserved and that duplication remains visible and governed. The Virtualization Layer functions as the exit point of the architecture. It enforces access control, data masking, and classification policies consistently across all consumers. By operating as a single serving interface, it prevents uncontrolled extraction and unmanaged replication. Consumers interact with data through defined interfaces, not through direct access to storage.
Control within the topology is enforced at three critical points: ingestion, cross-zone movement, and consumption. Data does not enter the architecture without passing through the Integration Hub. It does not move across zones without controlled pathways. It is not consumed outside the Virtualization Layer. These constraints define how the system operates. They are not optional. Metadata continuity spans all layers of the topology. From ingestion through transformation to consumption, lineage, ownership, and processing logic are recorded consistently. This provides a complete and traceable view of how data is derived and used across the enterprise. Without continuous metadata, structural control cannot be maintained.
Governance within this topology is enforced structurally
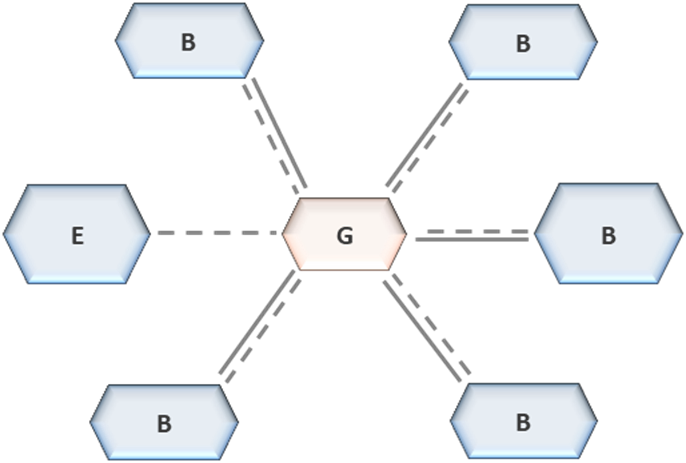
.Cost is embedded within the topology as a governed attribute. Enterprise-level environments operate as shared platforms, while domains are accountable for their own resource consumption within Business Zones. This separation ensures that resource usage is visible and attributable. Without it, duplicated pipelines, redundant storage, and unnecessary compute become untraceable, leading to uncontrolled cost expansion. The architecture separates storage, compute, and governance into distinct planes. Storage manages datasets, compute executes workloads, and governance operates across both through metadata and control mechanisms. This separation allows each plane to evolve independently without disrupting the structural integrity of the system. It ensures that control remains consistent even as technologies change.
Adoption of this topology requires enforced sequencing. Ingestion control must be established first, ensuring that all data enters the system through governed pathways. Zonal boundaries must then be defined to structure how data is transformed and accessed. The unified consumption layer is introduced after these controls are in place. If this sequence is not followed, domains establish independent pipelines and consumption patterns before structural boundaries exist, and the architecture reverts to decentralized behavior. This topology is the structural backbone of DAC. It defines how data flows through the system, where control is applied, and how consistency is maintained across distributed environments. It enables analytical scale without sacrificing traceability or governance. Federation without enforced topology does not function as architecture. It remains a conceptual model dependent on coordination and alignment. Topology makes federation operational by embedding control within the structure of the system.
Structure determines behavior. Without enforced topology, architecture does not govern.
4. The Integration Hub: Structural Control of Ingestion
In a federated architecture, structural control begins at ingestion. If the point of entry is not governed, no downstream mechanism can restore coherence. Variation introduced at ingestion propagates across every subsequent transformation, replication, and consumption path. Control applied later can only observe divergence, not prevent it. For this reason, DAC establishes ingestion as a non-negotiable control point and enforces a single ingestion authority: the Integration Hub
.The Integration Hub is the mandatory boundary through which all data enters the architecture. It is not an optional integration layer or a convenience mechanism. It defines the only permissible path from source systems into the governed environment. Direct connections from analytical platforms, domain environments, or AI systems to enterprise sources are not permitted. Each source is integrated once through a centrally visible and governed process, ensuring that ingestion logic is defined, consistent, and controlled at the architectural level. This constraint eliminates uncontrolled pipeline creation at the point of entry. Without a single ingestion authority, multiple teams establish independent connections to the same sources, introducing variation in extraction logic, refresh cadence, filtering conditions, and interpretation. These differences are embedded into datasets before any transformation occurs, making alignment downstream impractical. The Integration Hub removes this condition by enforcing a single, canonical ingestion pathway for each source.
Control at this boundary extends beyond initial ingestion. All physical data movement across the architecture is routed through the Integration Hub and re-ingested under the same governance conditions. Data does not move directly between zones or environments through independent pipelines. Any materialization or redistribution of data is treated as a new ingestion event, subject to the same validation, metadata registration, and control mechanisms. This ensures that movement does not introduce untracked divergence.
Within the Integration Hub, ingestion is structured through defined layers that enforce traceability and standardization. The landing layer preserves raw data in its original form, maintaining an immutable record of source input. This layer provides the basis for traceability, allowing all downstream datasets to be linked back to their origin without loss of fidelity. It is not used for transformation or consumption. Its purpose is preservation and reference. The staging layer enforces structural normalization and validation. Data is transformed into standardized formats, quality checks are applied, and metadata is registered. Structural inconsistencies, missing attributes, and quality violations are detected and resolved at this stage. Data that does not meet defined conditions does not proceed further into the architecture. Entry is conditional, and acceptance is governed by enforceable rules rather than discretionary decisions. Centralizing these layers prevents duplication of ingestion preparation across domains. Domains do not define their own landing or staging processes. They do not implement independent validation logic or metadata definitions. These responsibilities are architectural and must remain consistent. If domains replicate ingestion preparation, structural alignment is lost at the earliest stage, and divergence becomes embedded in every downstream process
.A critical operational principle within the Integration Hub is ingestion ownership. The first domain or consumer requesting a dataset assumes ownership of its ingestion pipeline. This ownership includes responsibility for maintenance, performance, and cost. Subsequent consumers do not establish new ingestion pipelines for the same source. They consume the existing pipeline. This eliminates duplication at the ingestion level and ensures that each dataset has a single controlled entry point into the architecture. Ownership is not static. It may transfer as organizational structures or usage patterns evolve. However, transitions are governed and must preserve continuity of control. Changes to ownership do not result in new pipelines or alternative ingestion pathways. They reassign responsibility within the existing structure, maintaining consistency in how data enters the system.
The Integration Hub is also the enforcement point for data quality and metadata continuity. Validation at ingestion ensures that structural anomalies are identified before data is propagated. Metadata - covering schema, lineage, ownership, classification, and processing context - is registered as part of the ingestion process. Data that is not registered within this framework does not exist within the governed architecture. It cannot be consumed, moved, or transformed through controlled pathways. This establishes metadata as a structural requirement rather than a supplementary artifact. Every dataset entering the architecture carries defined attributes that enable traceability, governance, and interoperability. Without this continuity at ingestion, downstream processes cannot maintain consistent lineage or enforce control.
Cost accountability is embedded at this boundary. Ingestion pipelines are centrally defined and owned, making resource consumption visible and attributable. Compute, storage, and data transfer costs associated with ingestion are linked to specific datasets and owners. Without this structure, independent pipelines proliferate, and resource usage becomes opaque. Cost increases without corresponding visibility, making optimization reactive and incomplete. The Integration Hub also defines constraints for AI workloads. Data science environments, model training pipelines, and experimentation platforms are not permitted to extract data directly from source systems. All datasets used for experimentation and training must originate from governed ingestion. This ensures that models are built on consistent, traceable data and that training pipelines do not introduce parallel ingestion pathways. Without this constraint, AI environments create isolated data ecosystems that diverge from the governed architecture.
By enforcing a single ingestion authority, the Integration Hub preserves both structural and semantic consistency. All downstream transformations, models, and analytical outputs are derived from data that has passed through a consistent entry process. This establishes a stable foundation for the entire architecture. Variation is controlled at the source rather than corrected after propagation.
The absence of this control leads to immediate and irreversible divergence. Independent ingestion pipelines introduce differences that cannot be reconciled without reprocessing data from origin. Downstream governance mechanisms - whether applied in transformation layers, semantic models, or consumption interfaces - operate on data that is already inconsistent. They cannot restore alignment because the inconsistency is embedded at entry. Architectural approaches that allow distributed ingestion attempt to manage this condition through standards, guidelines, or coordination. These mechanisms do not enforce behavior. Teams implement ingestion according to local interpretations, and variation accumulates. Over time, multiple representations of the same source data emerge, each governed independently. The architecture loses its ability to define a consistent baseline.
Centralized ingestion without structural enforcement does not resolve this problem. If ingestion processes are centralized but allow variation in implementation, the same divergence occurs within a single environment. Control must therefore be explicit and enforced. The Integration Hub does not provide centralized capability alone. It enforces uniform behavior at the point of entry. As data ecosystems expand and new sources are integrated, the importance of this boundary increases. Each additional source introduces potential variation. Without enforced ingestion control, the rate of divergence scales with the number of sources and consumers. The Integration Hub contains this growth by ensuring that each new source is integrated once and governed consistently from the outset.
Adoption of this model begins at the ingestion boundary. Structural control must be established before downstream environments are expanded or federated. If domains are allowed to define ingestion independently before this boundary is enforced, multiple pipelines become embedded in operational workflows. Retrofitting control becomes disruptive and often incomplete. Establishing ingestion authority first creates a stable foundation for subsequent architectural elements. Zones, virtualization layers, and cross-domain controls depend on consistent input. Without controlled ingestion, these elements operate on divergent datasets and cannot maintain coherence.
The Integration Hub is not a supporting component within the architecture. It is the control point that anchors governance, lineage, and consistency across the system. It defines how data enters, how it is registered, and how it becomes part of the governed environment.
Architectures that do not enforce ingestion control cannot sustain coherence under scale. They inherit divergence at entry and propagate it across every layer. The Integration Hub addresses this by making ingestion a structural operation, governed by explicit and non-negotiable constraints.
5. Enterprise and Business Zones: Federated Ownership Model
A federated architecture requires explicit separation between domain execution and enterprise control. Without this separation, organizations are forced into unstable extremes. Centralizing all analytical activity within a single environment constrains adaptability and limits domain responsiveness. Allowing domains to operate independently without structural boundaries removes discipline and produces divergence. A federated model must therefore define where autonomy is permitted and where it is constrained. DAC establishes this through a zonal structure that enforces ownership boundaries while preserving coherence across the system

.The zonal model is composed of two distinct constructs: the Enterprise Zone and Business Zones. These are not infrastructural partitions or deployment patterns. They define how ownership is distributed and how control is applied. Each zone represents a governed environment with specific responsibilities, constraints, and operating conditions. Together, they establish a system in which domains can execute independently without altering the structural behavior of the architecture. The Enterprise Zone is the corporate analytical layer. It is the environment where cross-domain integration occurs and where consistency across the enterprise is enforced. Datasets within this zone are aligned to shared models, governed reference data, and enterprise-level definitions. This is not an optional consolidation layer. It is the location where enterprise coherence is materialized. Analytical outputs that require cross-domain alignment, regulatory reporting, or enterprise-wide intelligence depend on this environment. In this zone, variation is not permitted. Consistency is mandatory.
The Business Zones represent domain-aligned environments where operational ownership resides. Each domain controls its datasets, transformation logic, and analytical workloads within its assigned zone. This control enables domains to operate with the flexibility required to meet their specific objectives. However, this autonomy is bounded. Domains do not define structural rules. They execute within them. Metadata standards, access control policies, lifecycle governance, and structural constraints are enforced at the architectural level and apply uniformly across all Business Zones. This separation between ownership and governance is the defining characteristic of the federated model. Domains own execution. They do not own structural control. They cannot define how data enters the system, how it is exposed to other domains, or how it moves across the architecture. These elements are enforced centrally and apply consistently regardless of domain-specific requirements.
If domains assume control over these aspects, the architecture transitions from federated to decentralized behavior.
The boundary between zones is strictly governed. Business Zones do not establish direct ingestion pipelines to source systems. They do not exchange data through independent mechanisms. All data entering the architecture or moving between zones must pass through the Integration Hub. This constraint ensures that ingestion and inter-zone movement remain controlled and traceable. Without it, domains create parallel pathways for data movement, introducing duplication and breaking lineage. Data produced within a Business Zone does not become available to other zones through direct access. It must be published through governed pathways. Publication is a controlled operation that registers datasets, enforces metadata standards, and ensures that outputs conform to structural requirements. Once published, data can be accessed by other zones under controlled conditions.
Zones operate as coordinated environments, not as independent systems exchanging data through unmanaged pathways.
The Enterprise Zone consumes data through these governed pathways. It does not extract data directly from Business Zones. Cross-domain datasets are constructed from published data that has been validated and registered within the architecture. This ensures that enterprise-level outputs are derived from controlled inputs. It prevents the introduction of untracked dependencies between zones and maintains consistency in how data is integrated. Logical access across zones is provided through the Virtualization Layer. This layer enables read-only access to datasets without requiring physical replication. Consumers access data through defined interfaces that enforce access control, masking, and classification policies. This approach decouples consumption from storage, allowing domains and enterprise workloads to access shared data without introducing duplication.
Physical data movement is governed independently of logical access. When datasets must be materialized across zones, the movement occurs through controlled pathways that preserve lineage and metadata continuity. Direct replication between zones is not permitted. This separation between logical access and physical movement prevents dependency sprawl and ensures that all materialization remains visible within the architecture. Cost governance reinforces ownership boundaries within this model. The Enterprise Zone operates as shared infrastructure, supporting cross-domain workloads and enterprise-level analytics. Its cost structure is centralized. Business Zones, by contrast, are accountable for their own resource consumption. Compute, storage, and processing costs incurred within a Business Zone are attributed to the owning domain. This separation ensures that domains are responsible for the efficiency of their operations and prevents cost from becoming opaque as the architecture scales.
Without this distinction, cost attribution fails.
Domains replicate datasets and execute transformations without visibility into existing assets, increasing consumption without accountability. The zonal model enforces cost ownership in alignment with execution ownership, ensuring that resource usage is both visible and controlled. Semantic consistency is maintained through shared metadata contracts and governed reference datasets. Domains are permitted to define local models within Business Zones, reflecting their specific analytical needs. However, when data is shared across domains or consumed within the Enterprise Zone, it must align with enterprise-defined semantics. Common business concepts, reference data, and classification rules are enforced to ensure interoperability.
Without this alignment, cross-domain analytics produce inconsistent results, even when structural constraints are maintained.
This model allows variation where it is appropriate and enforces consistency where it is required. Domains retain the flexibility to optimize for performance and use case requirements within their zones. They cannot redefine shared business concepts or alter structural rules that govern interaction with the rest of the architecture. The boundary between local optimization and enterprise consistency is explicitly defined and enforced. AI workloads operate within the same zonal structure. Domain-specific models are developed within Business Zones using governed datasets that originate from controlled ingestion. These models reflect domain-level requirements and operate within the constraints of the zone. Cross-domain models, which require integrated datasets and consistent semantics, are developed within the Enterprise Zone. This separation ensures that model training and execution remain aligned with the structural boundaries of the architecture. No independent AI environments are permitted outside this structure. Data science platforms, experimentation pipelines, and model training systems operate within Business Zones or the Enterprise Zone, depending on their scope. They inherit the same governance, metadata, and cost controls as other workloads. This ensures that AI does not introduce parallel data ecosystems that bypass architectural constraints.
Adoption of the zonal model requires structural enforcement. Business Zones must be defined along domain boundaries, establishing clear ownership of data and workloads. Ingestion must be controlled through the Integration Hub before domains are allowed to operate independently. The Enterprise Zone must be established to support cross-domain integration and ensure consistency. If domains are granted autonomy before these controls are in place, they establish independent ingestion and data exchange mechanisms. The architecture then reflects decentralized behavior rather than federation. This sequence is critical. Structural boundaries must be established before execution autonomy is expanded. Without enforced boundaries, domains optimize for local requirements and introduce variation that cannot be reconciled later. Federation cannot be achieved incrementally through coordination. It requires structural definition from the outset.
The zonal model defines how ownership is distributed and how control is maintained within a federated architecture. It allows domains to operate independently while ensuring that their operations do not alter the structural behavior of the system. It replaces reliance on coordination with enforced boundaries that define how data is managed across domains. DAC enforces this federated ownership model through explicit constraints. Domains execute independently within Business Zones, but they remain structurally bound by enterprise-defined rules. Data entry, cross-domain movement, and consumption are governed centrally and applied consistently across all zones.
Architectures that do not enforce these boundaries cannot sustain coherence under scale. Domain autonomy without structural constraint results in divergence. Centralized control without domain autonomy limits adaptability. The federated ownership model resolves this by separating execution from structural control and enforcing the boundary between them.
Scale amplifies both capability and risk. Without enforced ownership boundaries, that risk materializes as fragmentation. The zonal model ensures that expansion does not alter the structural integrity of the architecture.
6. Virtualization Layer: Unified Serving Plane
In a federated architecture, structural control must extend beyond ingestion and transformation to the point of consumption. Governing how data enters the system is insufficient if consumers can extract, replicate, or reinterpret data outside controlled pathways. Consumption is where divergence re-emerges if it is not constrained. DAC addresses this by enforcing a single, unified serving plane: the Virtualization Layer
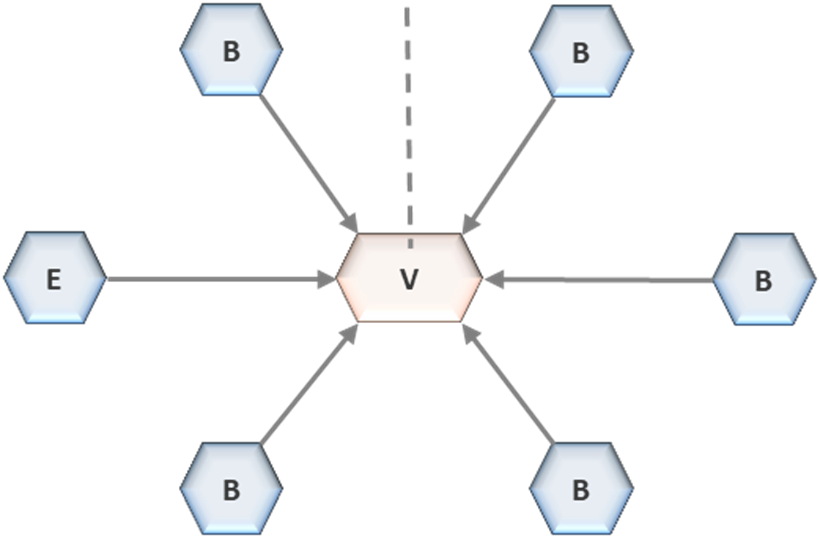
.The Virtualization Layer is the mandatory interface through which all data consumption occurs. Analytical tools, reporting platforms, applications, and AI workloads access data exclusively through this layer. Direct access to storage within Enterprise or Business Zones is not permitted. This constraint is structural. It ensures that consumption follows a controlled and observable pathway, eliminating the ability for consumers to bypass governance by interacting directly with underlying data stores. This design removes the variability that typically arises at the point of access. In unconstrained environments, consumers extract data into local contexts, reshape it according to specific needs, and persist independent copies. Each extraction introduces a new version of the dataset, often without lineage, governance, or visibility. Over time, consumption patterns create parallel data ecosystems that diverge from the governed architecture.
The Virtualization Layer eliminates this condition by defining a single, enforced access mechanism.
Data within this layer is exposed through read-only, virtualized representations. Consumers interact with logical views rather than physical storage. These views present data in a form aligned with metadata definitions, access policies, and classification rules. The underlying datasets remain unchanged. Consumers cannot modify data through the interface, nor can they persist derived copies within the governed architecture through this pathway. The read-only constraint is not a usability decision. It is a structural requirement. By preventing write operations, the architecture ensures that consumption does not introduce new data states or uncontrolled transformations. Consumers are restricted to retrieval and computation within governed boundaries. This preserves the integrity of core datasets.
Cross-domain analysis is executed through federated query mechanisms within the Virtualization Layer. Data remains physically located within its respective zone, and queries are resolved by combining datasets logically at execution time. This approach avoids the need for physical consolidation while enabling integrated analysis across domains. Domain autonomy is preserved, as datasets are not moved or duplicated for the purpose of consumption. This separation between logical access and physical movement is fundamental. Logical access is provided through virtualized views. Physical movement occurs only through governed pathways defined elsewhere in the architecture. When data must be materialized - whether for performance optimization, regulatory requirements, or persistent storage - it is transferred through controlled mechanisms that preserve lineage and metadata continuity. Consumption interfaces are not used for replication.
The Virtualization Layer enforces governance dynamically at the point of access. Access control policies determine which datasets and attributes are visible to each consumer. Data masking is applied based on classification rules, ensuring that sensitive information is protected. These controls are evaluated at query execution time, providing consistent enforcement regardless of the consuming application or workload. Governance is embedded in the access mechanism rather than applied externally. All access through this layer is observable. Queries, dataset usage, and access patterns are recorded centrally. This provides a complete view of how data is consumed across the enterprise. It enables monitoring of usage trends, detection of anomalous access patterns, and attribution of consumption to specific domains or users.
Visibility is a direct consequence of enforcing a single consumption pathway.
Semantic consistency is maintained through controlled exposure. Data presented through the Virtualization Layer conforms to shared metadata definitions when cross-domain alignment is required. Domain-specific variations remain internal to Business Zones and are not exposed unless they meet defined structural and semantic conditions. This ensures that consumers interacting with shared datasets receive consistent representations, even when underlying implementations differ. The Virtualization Layer defines a single consumption pathway for all workloads. Business intelligence tools, reporting systems, and machine learning pipelines access data through the same interface. There are no alternative mechanisms for retrieving data within the governed architecture.
This constraint is particularly significant for AI workloads. Data science environments often require flexible access to diverse datasets for experimentation and model training. In the absence of control, these environments establish independent data acquisition pipelines, creating isolated feature stores and training datasets that diverge from governed sources. The Virtualization Layer prevents this by enforcing that all data used for experimentation and training is accessed through the same controlled interface or originates from governed ingestion pathways. By integrating AI workloads into the same consumption model, the architecture ensures that models are built on consistent, traceable data. Feature engineering, model training, and evaluation operate within the same governance, metadata, and access control frameworks as other analytical processes. This eliminates the creation of parallel data ecosystems specific to AI.
The Virtualization Layer also decouples consumption from underlying infrastructure. Consumers interact with logical representations of data rather than with physical storage or compute resources. Changes in storage technologies, data formats, or processing engines do not affect the consumption interface. This abstraction allows the architecture to evolve without disrupting analytical workloads. Stability at the interface preserves continuity for consumers even as the system changes internally. Adoption of the Virtualization Layer follows the establishment of ingestion control. Once data entry is governed through the Integration Hub, consumption must be constrained to prevent divergence at the point of use. If consumers are allowed to access data directly from storage before this layer is enforced, independent extraction patterns become embedded in workflows.
The sequence is therefore critical.
Ingestion establishes a controlled foundation. The Virtualization Layer ensures that this control is maintained during consumption. Together, they define the boundaries within which data operates. Skipping this sequence results in architectures where control exists at entry but is bypassed during use. The Virtualization Layer is not an optional enhancement. It is the control point that governs how data is accessed and interpreted across the architecture. Without a single, enforced, read-only consumption pathway, coherence cannot be sustained. Consumers will extract and replicate data to meet local requirements, reintroducing fragmentation regardless of upstream controls.
Architectures that rely on multiple access mechanisms cannot maintain consistent governance.
Each pathway introduces variation in access control, data interpretation, and visibility. Over time, these variations accumulate, and the architecture loses its ability to provide a unified view of data consumption. The Virtualization Layer eliminates this condition by enforcing a single interface. All data access is mediated, observable, and governed. Logical access is decoupled from physical storage. Replication is controlled. Semantic consistency is maintained at the point of exposure. Control at consumption completes the structural model.
Data enters through governed ingestion, moves through controlled pathways, and is accessed through a unified serving plane. Removing control at any of these points reintroduces divergence. The Virtualization Layer ensures that consumption remains within the boundaries defined by the architecture, preserving coherence as the system scales.
7. Absorbing AI Within Federation
Artificial intelligence does not require a separate architectural domain. It introduces new processing patterns, not new structural requirements. In a federated architecture, AI is treated as a workload class operating within the same boundaries that govern all analytical processes. This is not a design preference. It is a structural condition. If AI operates outside the architecture, it introduces independent ingestion, storage, and transformation pathways that undermine coherence. The perception that AI requires dedicated platforms has led organizations to create isolated environments for experimentation, model training, and feature engineering. These environments are typically provisioned to provide flexibility and speed, but they do so by bypassing established controls. Data is extracted from governed systems, copied into local environments, and reshaped independently. These actions introduce new versions of datasets that are not aligned with the architectural model.
The consequence is immediate divergence. Independent extraction pipelines introduce variation at the point of data acquisition. Feature engineering processes operate on datasets that are no longer synchronized with governed sources. Models are trained on data that cannot be traced consistently across environments. These conditions are not temporary. Once established, they become embedded in operational workflows. The structural issue is not the presence of AI workloads. It is the introduction of parallel data ecosystems to support them.
Dedicated AI platforms replicate ingestion, storage, and governance capabilities already defined within the architecture.
Each replication introduces a separate control surface, weakening visibility and consistency. Over time, the architecture no longer represents a single system. It becomes a set of loosely connected environments, each maintaining its own data and logic. DAC eliminates this condition by requiring that all AI workloads operate within the existing federated structure. There are no separate AI environments. Enterprise and Business Zones provide the execution contexts for all AI development, training, and inference. This ensures that AI operates on governed datasets and remains subject to the same structural constraints as other analytical processes. The placement of AI workloads follows the same zonal logic that governs other operations. Cross-domain models are developed within the Enterprise Zone, where integrated datasets and aligned semantics are available. Domain-specific models are developed within Business Zones, where local data and transformations are controlled by the domain.
This separation ensures that model scope aligns with data scope.
Cross-domain dependencies required for AI are resolved through governed pathways. Data required from multiple domains is integrated through the same controlled mechanisms that support enterprise analytics. Direct access between zones for the purpose of model training or feature extraction is not permitted. Allowing such access would bypass structural controls and reintroduce untracked dependencies. All datasets used for AI - whether for training, validation, or feature engineering - originate from governed ingestion. Data scientists do not extract data directly from source systems or establish independent acquisition pipelines. They access datasets through the same controlled pathways available to other consumers. Feature engineering operates within zone boundaries. Features are derived from governed datasets and remain linked to their source data through metadata and lineage. Independent feature stores that exist outside the architecture are not permitted. When features are treated as separate, unmanaged assets, they become disconnected from source data and cannot be reused consistently across models. By enforcing feature development within zones, features remain governed and interoperable.
Features are registered as data assets within the architecture.
Their definitions, transformations, and dependencies are captured in metadata alongside other datasets. This ensures that feature reuse is controlled and that changes to underlying data can be traced through to dependent models. Model artifacts are also managed within the zonal structure. Models, training datasets, evaluation metrics, and configuration parameters are stored in the zones where they are developed. There are no separate storage environments for AI artifacts. This ensures that models remain connected to the datasets and transformations from which they are derived. Separation of model artifacts from governed data introduces gaps in lineage and limits visibility into model behavior. AI workloads do not introduce independent storage layers. Data scientists operate directly on datasets that exist within the architecture. They do not create persistent copies of data in isolated environments for the purpose of experimentation. This constraint prevents duplication and ensures that all data used in AI workflows remains governed. It also eliminates the need to reconcile differences between local and governed datasets.
Inference follows the same architectural pathways as other analytical outputs. Predictions generated by models are exposed through the Virtualization Layer. They are subject to the same access control, masking, and classification policies as any other dataset. Independent mechanisms for distributing model outputs are not permitted. This approach ensures that AI outputs remain integrated within the architecture. Predictions can be traced back to the models that produced them, the features used during training, and the source data from which those features were derived. This continuity is essential for auditability, compliance, and operational reliability. Metadata continuity extends to all components of the AI lifecycle. Models, features, training datasets, and transformation logic are registered alongside other architectural elements. This provides a complete lineage from source data through feature engineering to model outputs.
The AI lifecycle - development, training, deployment, monitoring, and retraining - operates entirely within the zonal structure. Each stage is governed by the same controls that apply to other workloads. Alternative lifecycle pathways, where models are developed or deployed outside the architecture, are not permitted. Such pathways introduce inconsistencies that cannot be reconciled within the governed system. As AI adoption scales, the pressure to create independent environments increases. Teams seek flexibility to experiment and iterate rapidly. Without structural constraints, this results in the proliferation of isolated environments, each with its own data and models. These environments may deliver short-term capability, but they introduce long-term fragmentation that cannot be contained through governance. Embedding AI within the federated architecture addresses this pressure by providing controlled flexibility. Domains retain the ability to develop and optimize models within their zones. Cross-domain capabilities are supported through the Enterprise Zone. All operations occur within defined boundaries that preserve coherence.
These constraints are not restrictive.
They define the conditions under which AI can operate without introducing divergence. Removing them results in parallel systems that compete with the architecture rather than extending it. AI does not introduce new structural requirements. It amplifies existing weaknesses. Where ingestion is uncontrolled, AI accelerates data extraction. Where movement is ungoverned, AI introduces new dependencies. Where consumption is unconstrained, AI creates isolated outputs.
The presence of AI exposes whether structural control exists.
DAC addresses this by embedding AI within the same enforced structure that governs all data operations. AI workloads do not bypass the architecture. They operate within it. This ensures that as AI capabilities expand, they do so within a system that preserves consistency, traceability, and control.
Artificial intelligence does not break architecture. It reveals whether architecture was ever enforced.
8. Governance Blueprint and Enforcement
In DAC, governance is not defined through policy, documentation, or procedural oversight. It is embedded in the structure of the architecture. Data cannot enter, move, or be consumed unless it passes through enforced control points. Governance does not depend on adherence. It is executed through the way the system operates. If governance can be bypassed, it does not exist
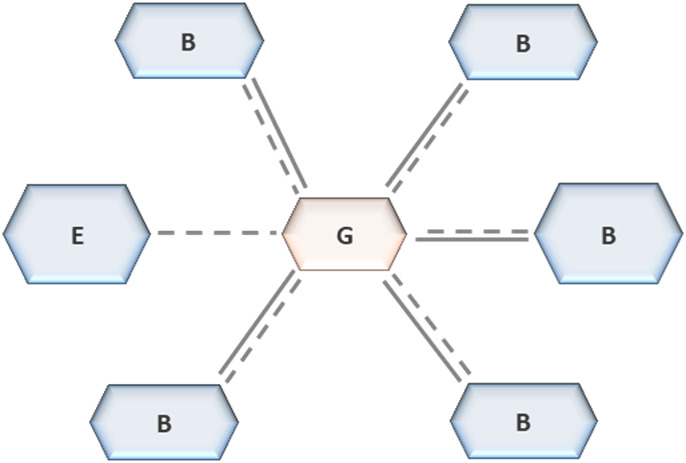
.The Governance Blueprint defines the structural constraints that apply across all layers of the architecture: the Integration Hub, Enterprise Zone, Business Zones, and the Virtualization Layer. These constraints are not recommendations. They define how metadata is managed, how data is classified, how access is controlled, how quality is enforced, and how lifecycle and compliance requirements are applied. Domains operate within these constraints, but they do not modify them. Governance is uniform, regardless of domain-specific implementation. At the centre of this blueprint is a mandatory metadata spine. No dataset, pipeline, transformation, or analytical artifact exists within the architecture without metadata registration. Metadata captures definitions, ownership, lineage, classification, and quality indicators. This registration occurs at ingestion and is maintained continuously across all zones. It extends beyond datasets to include AI artifacts such as models, features, and training lineage.
Metadata is not descriptive. It is the mechanism through which governance is enforced.
Data that is not registered in metadata is not part of the architecture. It is not visible through governed interfaces, cannot be accessed, and cannot participate in analytical processes. This condition is absolute. It ensures that all data within the system is traceable and governed from the point of entry through to consumption. Access control is enforced centrally across all layers through a unified identity and authorization model. Policies are applied consistently at ingestion, storage, transformation, and consumption. There are no alternative pathways for access. Direct interaction with data outside governed interfaces is not permitted. This ensures that all data access is mediated, controlled, and observable. The enforcement of governance is inseparable from the topology of the architecture.
The system defines where data can enter, how it can move, and how it can be consumed. These pathways are fixed. Domains cannot redefine them. The Integration Hub governs ingestion and cross-zone movement. The Virtualization Layer governs consumption. Data operations that occur outside these pathways are not supported. Governance is enforced through structure, not through oversight. Data quality is enforced as a condition of entry. At ingestion, datasets are validated against structural and semantic requirements. Data that does not meet these conditions is rejected and does not enter the governed environment. This establishes a baseline of consistency that is preserved across all zones. Domains may apply additional quality controls within their environments, but they cannot reduce or bypass enterprise-defined standards. This approach ensures that quality is not treated as a downstream concern.
It is embedded at the point where data becomes part of the architecture. Once admitted, datasets carry their quality attributes through all subsequent transformations and consumption processes. This continuity allows quality to be evaluated consistently across the system. AI artifacts are governed under the same structural model as datasets. Models, features, and training datasets are treated as governed assets. They must be registered in metadata, linked to their source data, and traceable across the lifecycle. Independent management of AI artifacts outside the architecture is not permitted. This ensures that model behavior can be understood, reproduced, and governed in the same way as other analytical outputs.
The governance model extends to deployment.
Promotion of datasets, transformations, or models into production environments is gated by structural validation. Metadata completeness, lineage traceability, access control enforcement, and data quality must meet defined conditions. Artifacts that do not satisfy these requirements do not progress. Deployment is not a discretionary process. It is controlled by enforceable criteria. Observability is inherent to this design. Because all ingestion, transformation, and consumption occur within governed pathways, the architecture provides a complete and continuous view of data activity. Dataset usage, transformation dependencies, access patterns, and model interactions are visible without additional instrumentation. This visibility is a direct result of enforcing a single structural model for all operations. The elimination of bypass mechanisms is a defining characteristic of the Governance Blueprint.
Shadow pipelines, direct data extraction, unmanaged storage environments, and independent transformation processes are not supported. The architecture does not provide pathways for activity outside governed boundaries. All data operations must occur within the defined structure. This removes the need for reactive governance measures. When bypass is not possible, enforcement becomes inherent. Governance is no longer dependent on detecting and correcting deviations. It prevents them.
Adoption of this model requires establishing non-negotiable conditions at the outset. Metadata registration must be enforced for all data assets. Access control must be applied through a unified model. These elements define the baseline for governance. Without them, governance remains procedural and cannot scale as complexity increases. Deployment gating follows as a structural extension of these conditions. By enforcing validation before promotion, the architecture ensures that only governed and compliant artifacts become operational. This prevents the introduction of inconsistencies into production environments and maintains integrity across the system.
The Governance Blueprint defines governance as infrastructure.
It establishes the boundaries within which all data activity occurs. Data flows, analytical processes, and AI workloads are governed because the architecture enforces how they operate. There is no distinction between governance and system behavior. As the architecture scales, these controls remain consistent. Additional domains, datasets, and workloads operate within the same structural constraints. Autonomy is preserved within zones, but structural integrity is not compromised. Governance does not degrade as complexity increases because it is not dependent on coordination or compliance. Architectures that treat governance as policy cannot maintain this consistency. Policies rely on interpretation and adherence. As systems expand, adherence varies, and governance weakens. Structural enforcement removes this variability by defining what is possible within the system.
The Governance Blueprint ensures that governance is not an overlay applied to the architecture. It is the architecture.
9. Operational and Economic Implications
Architecture determines how systems behave under load and how cost accumulates as they scale. In DAC, operational responsibility and economic accountability are not managed through reporting, allocation exercises, or governance committees. They are enforced by structure. Every component has a defined role, every action occurs within a controlled pathway, and every cost is attributable to a specific owner. If responsibility and cost cannot be traced structurally, the architecture has already lost control.
The topology establishes ownership by location, not by agreement. The Integration Hub owns ingestion and cross-zone movement. The Enterprise Zone maintains enterprise-level datasets and cross-domain capabilities. Business Zones own domain transformations, models, and analytical workloads. The Virtualization Layer governs consumption. These responsibilities are fixed. They do not shift based on project needs or organizational preference. Structural position determines accountability, and that accountability is enforced through how the system operates. This eliminates ambiguity in operational ownership. Teams are responsible for the data assets, pipelines, and compute they execute within their zones. They do not negotiate ownership at runtime, and they do not inherit responsibility for operations outside their boundary. Cross-zone interactions do not rely on coordination between teams. They are resolved through governed pathways that define how data moves and how responsibility is maintained.
The primary constraint that anchors both operational discipline and cost control is singular ingestion.
Data enters the architecture once through the Integration Hub. Independent pipelines to the same source are not permitted. This removes the most common source of duplication and divergence. When multiple pipelines exist, each introduces its own extraction logic, refresh cadence, and processing cost. These differences propagate across the system, creating both inconsistency and unnecessary expenditure. Singular ingestion enforces a shared foundation. Downstream environments consume governed datasets rather than recreating ingestion. Domains do not replicate pipelines to meet local requirements. They operate on the same data entry point, ensuring that both structure and cost remain consistent. This constraint defines how data acquisition is performed across the architecture.
Cost follows directly from this model. The domain that initiates ingestion assumes ownership of the associated infrastructure. This includes compute for extraction and transformation, storage for landing and staging, and ongoing operational overhead. There is no shared or unallocated ingestion cost. If a domain requires higher ingestion frequency, additional validation, or increased data volume, it bears the corresponding cost. Responsibility is explicit. Subsequent consumers do not establish new ingestion pipelines. They consume existing datasets through governed pathways. Cost sharing between domains is handled through financial mechanisms external to the architecture. It does not result in duplication of pipelines or data. The architecture enforces reuse; cost distribution is managed outside the data flow. This establishes two non-negotiable conditions.
Data is ingested once, and all consumption is attributable. There is no concept of free data acquisition within the system. Every dataset has a defined owner, and every unit of compute or storage consumed can be traced to a specific domain or enterprise function. Without this alignment, duplication persists because the cost of redundancy is not visible to those creating it. Within Business Zones, domains operate under defined compute and storage allocations. All transformation processes, model training activities, and analytical workloads consume resources that are owned and funded by the domain. There is no unrestricted central compute pool that domains can draw from without accountability. Resource usage is directly tied to domain responsibility.
This constraint enforces operational discipline.
Domains must optimize their workloads because inefficiency results in direct cost impact. They cannot externalize the cost of excessive computation, redundant transformations, or unnecessary storage. The architecture ensures that operational decisions have immediate economic consequences. The Enterprise Zone operates under a different model. It functions as shared infrastructure supporting cross-domain integration, enterprise analytics, and regulatory requirements. Its cost is distributed across the organization, but its scope is constrained. It is not a general-purpose environment for domain workloads. It exists to maintain enterprise-level coherence and support use cases that require integrated data. This separation prevents the Enterprise Zone from becoming a default execution environment.
Data movement is governed with the same level of control. Physical transfer of data between zones occurs only through the Integration Hub and requires justification. Movement is not initiated as a convenience. It is a controlled operation that preserves lineage and ensures visibility. Uncontrolled replication between zones is not permitted. Logical access through the Virtualization Layer is the default mechanism for data consumption. Consumers access data without creating physical copies, reducing storage duplication and data transfer costs. This separation between logical access and physical movement ensures that replication occurs only when necessary and under governed conditions. When this constraint is not enforced, storage duplication increases without visibility. Data is replicated across environments to meet local needs, and each copy incurs storage and maintenance costs. Transfer costs accumulate as data is moved repeatedly across systems. These costs are often hidden because they are distributed across teams and environments. The architecture eliminates this by enforcing controlled movement and logical access.
AI workloads follow the same operational and economic model. Training, feature engineering, and inference consume compute and storage resources within the zones where they are executed. Domains are accountable for the cost of domain-specific models, while enterprise-level models operate within the Enterprise Zone under shared cost structures. There are no separate AI infrastructure environments that operate outside this model. This constraint prevents the accumulation of untracked cost associated with isolated data science environments. When AI workloads operate independently, they duplicate datasets, create separate storage layers, and consume compute resources without visibility. By embedding AI within the same structural boundaries, all resource usage remains attributable and governed.
Operational efficiency emerges from these constraints. Ingestion, transformation, and consumption follow defined pathways, eliminating ad hoc integration patterns and parallel systems. There is no need to reconcile multiple pipelines, align duplicated datasets, or manage conflicting transformations. The architecture reduces operational overhead by preventing the conditions that create it. Reliability is structured rather than managed. Ingestion pipelines within the Integration Hub operate as shared or dedicated infrastructure with defined service levels. Downstream environments depend on these pipelines, so improvements to ingestion propagate across the system. Stability at the point of entry ensures stability throughout the architecture. Audit and compliance are inherent properties of the system.
All datasets, transformations, and models are registered within the metadata framework, maintaining complete lineage from source to consumption. Audit processes do not require reconstruction of data flows across independent systems. Traceability is embedded in the architecture, enabling continuous compliance without additional effort. These constraints introduce trade-offs. Centralized ingestion restricts direct access to source systems. Unified consumption through virtualization may introduce latency compared to direct data access. Controlled data movement limits the ability to replicate datasets for local optimization. These limitations are not unintended consequences. They are enforced conditions that prioritize structural integrity, governance, and cost accountability over unrestricted flexibility.
Flexibility within this architecture is not eliminated. It is constrained to defined boundaries. Domains retain control over their transformations, models, and analytical processes within Business Zones. They can optimize execution, adjust processing logic, and evolve their workloads. What they cannot do is alter the structural rules that govern how data enters, moves, or is consumed. Adoption of this model begins with cost attribution at ingestion and enforcement of compute allocation within zones. Without clear ownership of cost, domains continue to create redundant pipelines and duplicate datasets because the economic impact is not visible. Once cost aligns with responsibility, duplication becomes self-limiting. Structural constraints reinforce themselves through economic accountability.
This alignment creates a system where operational discipline is not enforced through governance intervention.
It is a direct consequence of how the architecture is constructed. Teams operate within defined boundaries, costs are visible and attributable, and deviations are not possible without structural change. As the architecture scales, these properties remain stable. Additional domains, datasets, and workloads do not introduce uncontrolled cost or complexity because they operate within the same constraints. The system expands without altering its operational behavior.
In DAC, operational discipline and economic accountability are not outcomes that must be achieved through management. They are enforced properties of the architecture itself.
10. DAC Adoption and Architectural Doctrine
DAC adoption does not begin from a defined baseline. It is introduced into environments where architectural control has already been fragmented through independent ingestion pathways, uncontrolled data movement, and inconsistent consumption patterns. These conditions are not transitional artifacts; they are embedded in operational systems and cannot be removed prior to adoption. As a result, transition does not proceed through replacement, but through the progressive enforcement of structural constraints within a partially governed environment. Controlled and uncontrolled states coexist, and the architecture emerges through the reduction of permissible variation over time. This requires explicit sequencing, sustained enforcement, and acceptance of intermediate states that do not yet reflect full coherence. The objective is not immediate alignment, but directional convergence toward a system where structural control is uniformly applied.
Adoption is a structural intervention, not a deployment exercise.
New platforms do not create alignment. Additional tooling does not restore coherence. The architecture is established by enforcing constraints on how data enters, moves, and is consumed. Systems continue to operate during this process, but they do so under progressively restricted conditions. The architecture does not adapt to existing behavior. Existing behavior is constrained until it conforms. The system enters a dual-state condition. One part begins to operate under enforced structure. Another continues under legacy patterns. These states coexist. Data flows across both. Dependencies span both. This is not an exception. It is the expected state of any transition. The objective is not immediate uniformity, but directional control. The governed portion must expand. The uncontrolled portion must contract. Expansion of uncontrolled behavior is the primary risk.
If new workloads are allowed to replicate existing patterns, the architecture diverges faster than it converges. Independent ingestion continues. Unmanaged consumption persists. Parallel data paths multiply. The governed system becomes peripheral. This condition cannot be reversed through later alignment. It must be prevented at the point of introduction. Containment is therefore mandatory. Legacy systems may remain, but they are isolated. They do not define new patterns. They are not extended into new workloads. All new data activity must conform to enforced constraints from the outset. This creates a structural asymmetry. The past is tolerated. The future is controlled. This sequencing is not optional.
Entry is enforced first. Access is constrained next. Movement is governed after these controls are stable. Domain execution follows within defined boundaries. Analytical workloads, including artificial intelligence, are aligned last. Any deviation introduces alternative pathways that persist beyond the transition and undermine structural control. Enforcement must be absolute. Constraints applied selectively do not hold. The system will converge toward the least restrictive behavior available. If exceptions are introduced, they become alternative pathways. Once established, they are reused and expanded. Control becomes negotiated rather than enforced, and fragmentation resumes.
Exceptions are therefore temporary and governed. They are defined explicitly and scheduled for removal. Persistent deviation is not an operating model. It is structural failure. The architecture does not accommodate alternative pathways that achieve equivalent outcomes. There is one way data enters, a controlled way it moves, and a defined way it is consumed. Adoption is measured by convergence. The proportion of workloads operating within enforced constraints must increase continuously. The proportion operating outside must decrease. Absolute completion is not required at each stage, but direction is. If uncontrolled elements persist without reduction, the architecture is not converging. It is accumulating additional layers without resolving structural inconsistency.
This transformation is not driven by tooling.
Technologies may vary. Platforms may evolve. What changes is behavior. All systems must conform to the same structural rules regardless of implementation. The architecture governs how data flows, not which tools are used to process it. Completion is defined by elimination. Uncontrolled ingestion is removed. Unmanaged movement is eliminated. Ungoverned consumption is no longer possible. At this point, the system operates under a single set of enforced pathways. Federation becomes operational, not conceptual.
DAC defines both the constraint and the outcome. It does not describe how systems should behave. It enforces how they must behave. Systems that operate within these constraints remain coherent as they scale. Systems that do not are not partially aligned. They are outside the architecture.
There is no intermediate state. Structural control either exists or it does not.
11. Appendix with all diagram


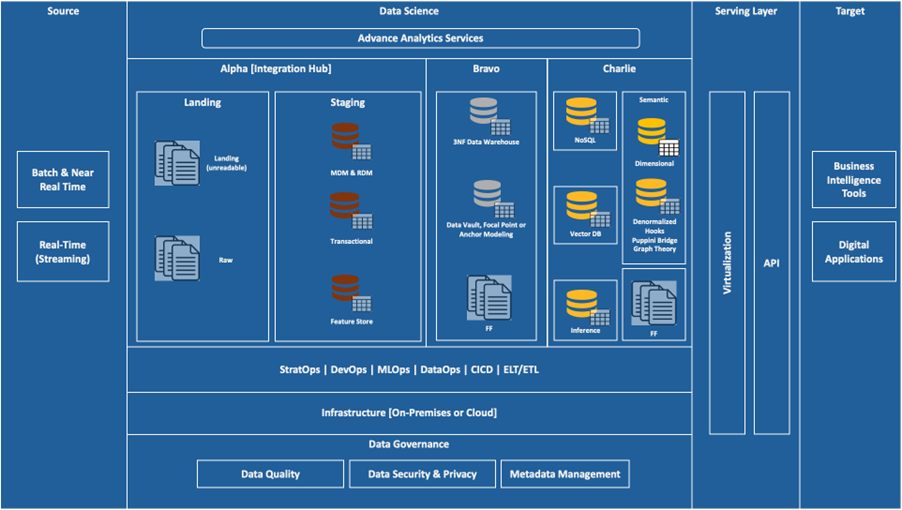
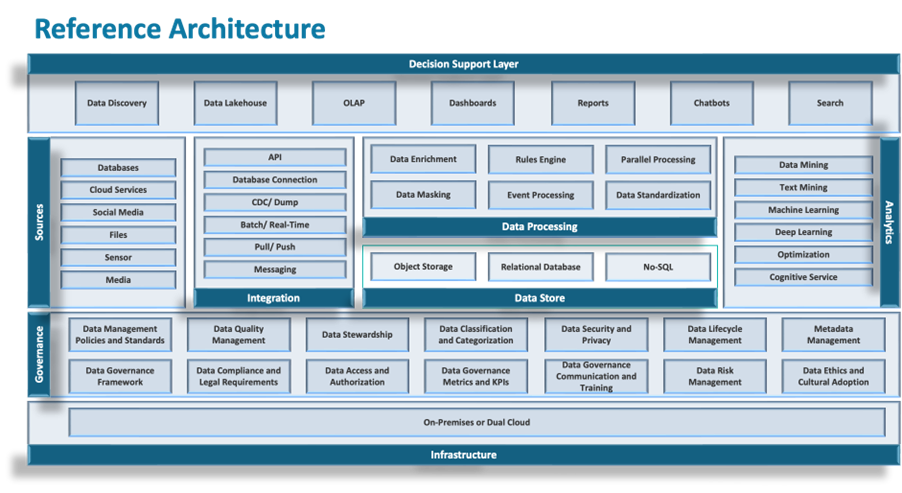
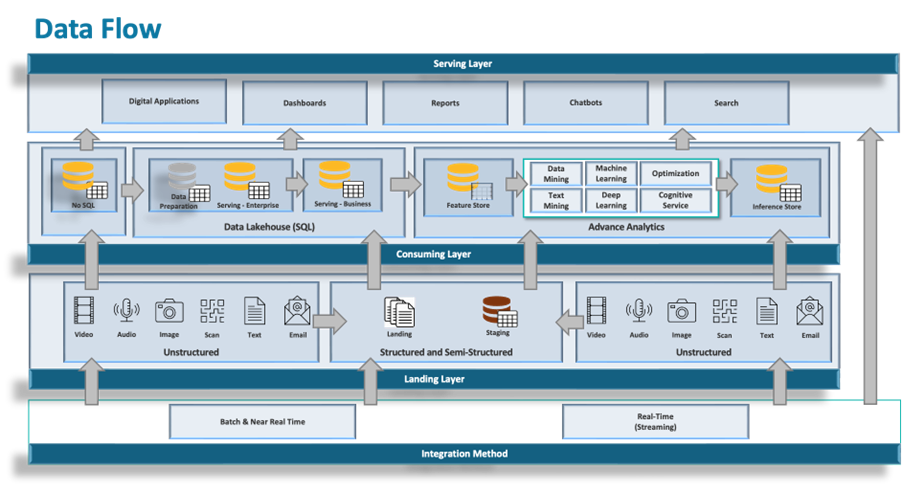
Who is Mustafa Qizilbash:
Mustafa Qizilbash is a Data and AI architecture professional, with more than 25+ years of experience, focused on redefining how modern enterprises design and operationalize data ecosystems. His work centres on creating practical architectural models that balance decentralized domain ownership with centralized governance—enabling organizations to scale data, analytics, and AI in a controlled yet flexible manner. Mustafa’s contributions to the field include Five books on Data & AI, over 1000+ publications, and Three patents, mentioned below. With experience spanning more than Seven countries, he has worked with leading global enterprises such as Oracle, IBM, Teradata, Petronas, Hong Leong Bank and many others.
He is the originator of the Data & AI Cognitive (DAC) Architecture, a structural approach to integrating AI within enterprise data platforms, along with the Value Discovery Canvas (Four 4s Formula) and the Productionizable Viable Product (PVP) Approach, which collectively bridge the gap between business intent and production-grade implementation.
Mustafa is also actively engaged as an advisor with Your Partner Technologies ( https://www.yourpartnertechnologies.com ), supporting enterprise-scale Data & AI initiatives. In addition, he hosts the podcast series “Let’s Talk About Data!” ( https://www.youtube.com/@letstalkaboutdata ), where global Data & AI leaders from over 35 countries share insights, experiences, and perspectives on the evolving data landscape.
Why Him!
Most businesses are already making decisions, but they don’t fully trust the data behind them. The issue isn’t a lack of data; it’s that different reports don’t match, definitions vary, and teams end up debating numbers instead of acting.
He help companies make faster, more confident decisions by ensuring they can trust their data. He typically come in as a Data and AI Professional/Advisor, leading focused engagements to identify where trust breaks across dashboards, reports, definitions, and data sources, and fixing those gaps end-to-end.
The engagement starts with the Directors and C-Level executives where decisions are frequent and the cost of being wrong, or slow is high. He works closely across all levels to uncover where numbers don’t align, where gaps become visible quickly. From there, IHealign business and IT around a single, reliable view of the data.
The result is simple: when a number shows up in a meeting, nobody questions it, they act on it.

 | A guest post by
|