
BUILDING THE TEXTUAL WAREHOUSE

One day someone wakes up in the corporation and they can’t find information in a document that is needed. They know that the information exists somewhere but they can’t find it. And in doing so, important business decisions are not made and opportunity is lost.
The simple fact that information exists in the corporation in the form of documents and no one can find them is a fact of life for large corporations. Losing information in documents(or having information that can’t be found) is simply a way of life.
But does it have to be that way? No, it does not. In order to understand that there is a solution to the problem of finding data that already exists in the corporation in documents, consider the following scenario.
Some of the data that is misplaced is of the transactional variety. The problems of organizing and finding operational, transaction based data is well documented. Data dictionaries, repositories and directories have been around for as long as there have been computers. But there is another type of data that has almost gone unnoticed, and that is document based textual data. For a variety of reasons, data based in a document is as slippery as a jumping fish flopping on the banks of a stream.
DOCUMENTS
So lets focus on documents in the corporation. When a document is created or is passed to the corporation it looks like -

The document can be about anything. It can be about an insurance policy. It can be about a contract. It can be about the terms of a sale. There are absolutely no restrictions as to what a document can contain.
The only assumption made in this paper is that there is something of business importance contained in the document. Otherwise there is no point in capturing the document. In some cases there is a lot of business importance contained in the document. In other cases there is less business importance. But somewhere, to some extent, there is something of business importance in the document.
TWO TYPES OF TEXT
So what happens to the document once it enters into the halls of the corporation? The document is essentially divided into two types of data –
Identifying data, and
Simple text
This division is shown -

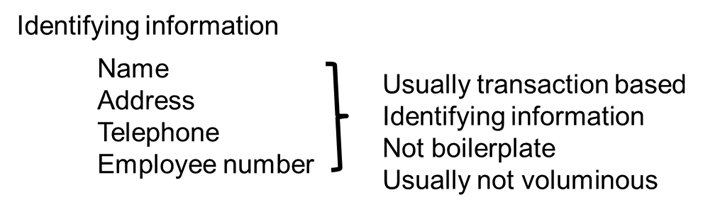
Identifying information includes such information as name, address, telephone number, email address, and so forth. It may also include information about employee number, social security number, patient number, account number or other information. The purpose of the identifying information is to allow one document to stand out from all other documents.
The identifying information for one type of document can be wildly different from the identifying information about another document. There is seldom any uniformity of identifying information when taken from one document type to another.
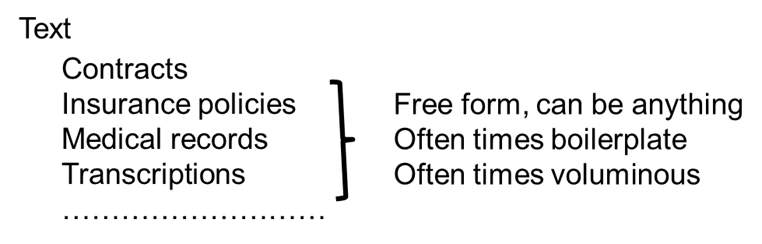
The other kind of information found in a document is the simple text. The simple text is descriptive information about the transaction that is being memorialized or the business activity that is being described. In the case of insurance, it might be the insurance policy itself. In the case of a contract it may be terms, conditions, prices, and so forth.
Usually there is a lot more information in the simple text than there is in the identifying information.
Once the document is entered into the domain of the corporation, it is captured. The capture consists of taking the identifying information and placing the identifying information in a standard data base. Typical of the contents of the data base are –
Name
Address
Telephone
Social security
In addition, information about the transaction or other business activity is typically captured. Typical information might be –
Date of transaction
Service or product purchased
Amount of purchase
Terms of purchase
Identifying information and other transaction information from the document is lifted and placed into a data base.
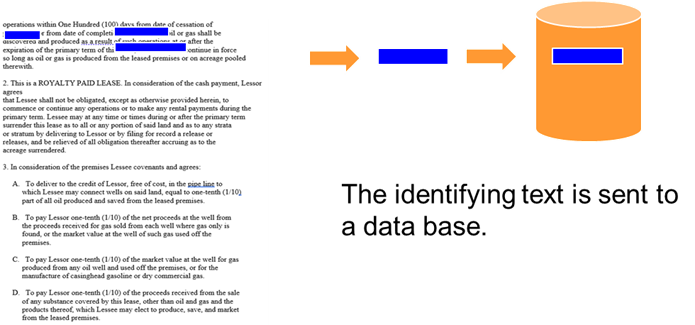
The information that is captured from the document includes identifying information, transaction information, and anything else needed for the day to day operational processing initiated by the document.
BUILDING THE DATA BASE
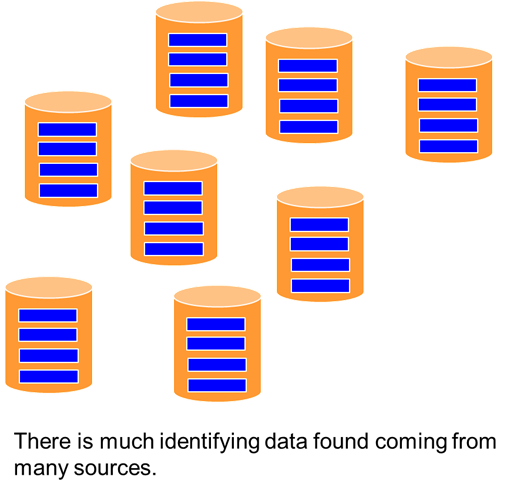
But the identifying information captured in a data base is not just for one document. The information captured from the document is normally from a LOT of documents. All the customers, all the sales, all the transactions are captured in these data bases.

WHAT HAPPENS TO THE DOCUMENT?
Then what happens to the document that generated the identifying information into the data base after the identifying information has been lifted into a data base? There are several things that may happen to the document.
The document may be discarded. In this case, it is felt that all the information that is needed has already been captured and that there is no need to retain the document.
But there may be reasons why the document may still contain valuable information. In this case the document may be subjected to OCR – optical character recognition. In this case an electronic image of the document may be captured and stored.
Or the document may be stored in a paper format, typically residing in a filing drawer or a folder.
There may be other dispositions of the document, but these are the most common.

So what happens when someone needs to retrieve one of these documents? As long as there are not too many documents and as long as the data is reasonably current, there is usually not a problem. But problems start to arise as there starts to appear many documents and/or documents start to age.
THE INFORMATION ENVIRONMENT OVER TIME
The first stage in the growth of the environment is for the data bases that contain the identifying data to start to grow. In the beginning there are a manageable number of data bases. But over time – for a variety of reasons – the number of operational data bases increases. And the data found in those data bases starts to age.
Most IT departments are geared to handle very current data. Most IT departments do not handle older or archival data well.
These many operational data bases that collect over time have many problems typically associated with them. The biggest problem is that the many operational data bases have been created while integration across the entire environment is never considered. Each application is a world unto itself. This environment is often called the “siloed environment” or the “spider’s web environment.” The issues of the siloed environment or the spider’s web environment are amply discussed elsewhere.
One of the approaches that is used for siloed systems is to try to address this problem using a repository or directory (or data dictionary) that points to where the operational data lies.
But over time the amount of data – in operational files and the amount of text – continued to increase. Each new record and each new file piles up on top of what is already there
.Soon the information environment was in a big mess. Nobody could find anything.
The piling on of new data over old data is roughly equivalent to what happens to archaeological artifacts over time. Each year a new layer of dust and dirt falls on the artifact. In order to retrieve the artifact, it is necessary to remove all the dirt that has collected over it over time.
The mess was/is being created is true for all data, including the text data that had been stored.
FINDING TEXT
If text has been discarded, it could – of course – not be found.
If text was stored as paper it was truly difficult to find a single document. To find paper documents required searching manually through a myriad of file cabinets. As long as there are only a few cabinets to be searched, a manual search is acceptable. But once there starts to be many cabinets, a manual search is simply not acceptable.
Many organizations stored text as an OCR document (typically in a .pdf file). The thought when the textual documents were stored by OCR was that it would be easy enough to find a document if there was an OCR record of it.
But there are (at least!) two problems with taking an OCR snapshot of documents.
The first problem is that in its simplest form, OCR is nothing but a snapshot – an image. In order to understand what is in the OCR document you have to have read – manually – the document. In order to be successfully read, you have to create an electronic text understanding of what is in the document that has undergone OCR processing. When you create OCR, it is true that you have a copy of the information on the document. But in order to do anything with the snapshot you have to either manually read the document or subject it to electronic texting.
With OCR you can ask the OCR technology to convert what text is recognizable into an electronic format. As long as the image is clear and as long as the text is in the right font and is readable, OCR does a good job of capturing the text that is in the image.
But just because text is captured and then electronically converted to text does not mean that it can be read or searched. Indeed, there are many reasons why electronically captured text cannot be analyzed. In order to be analyzed by the computer, the text needs to be disambiguated.
Disambiguation is a large topic which is addressed in textual ETL.
In a word, OCR does not live up to all the promises made by the OCR vendor. Just because you create an OCR record of a document does not necessarily mean that you can do anything with it.
What needs to happen is that the text found on the OCR documents need to be placed into a textual warehouse.

If you do not have a textual warehouse, in order to process text stored in OCR you have to end up reading the documents manually. And there is only a limited amount of analysis that can be done when reading text is done manually.
Reading documents manually works if there are a small amount of documents to be read. But what if there are many documents to be read? What if here is an avalanche of documents?

Making matters even worse is the case where the documents must be read under a deadline.

Or even worse what if you are looking for documents that have information scattered across multiple documents

In a word, manually reading documents is not a long term or staisfactory solution.
A CONTINUALLY ADVANCING PROBLEM
One solution is just to make do as best you can. Do whatever it takes to get to the next project. But kicking the can down the road only makes matters worse. Every month new data, new documents, and new projects pile onto what is already there. Each time new data is added, the problem of finding existing data becomes worse. Trying to ignore the root problem only makes matters incrementally worse. Each day, each month, each new document only increases the difficulty of find data that already exists in the corporation.

You arrive at the point where finding data that exists becomes a limiting factor in the ability to do business. You reach the point where finding data becomes a limiting factor of doing business.
Transaction based data – identifying data – suffers from the same problem. But transaction based data is usually a little easier to search than textual data.
A TEXTUAL WAREHOUSE
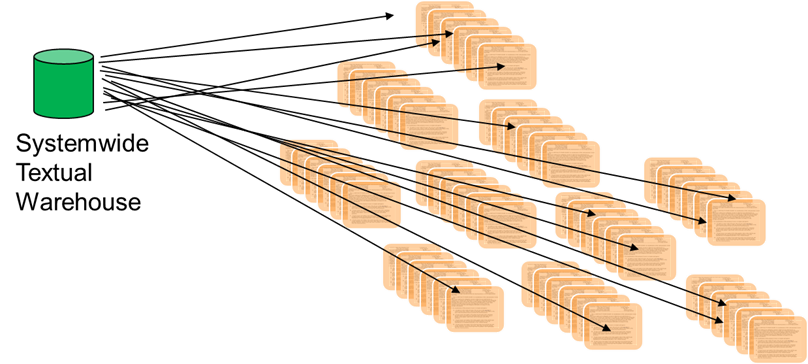
In order to address the problem of finding the textual data in your corporation, you need a textual warehouse. A textual warehouse is similar to a data warehouse except that it applies only to text and to documents.
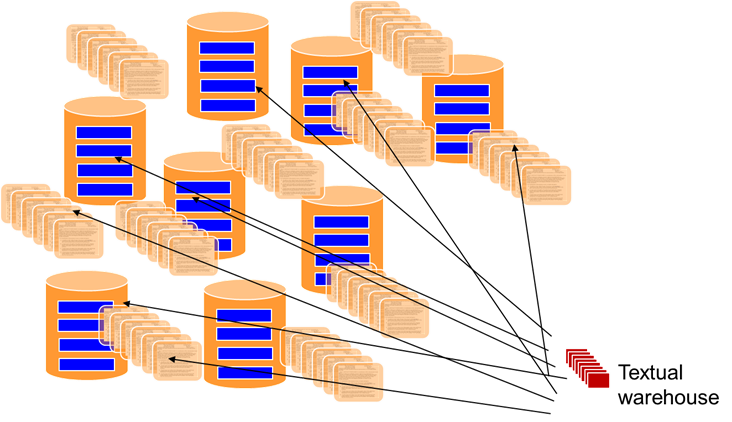
The textual warehouse is similar to a data warehouse except that it exists solely for the purpose of enabling the organization to find its text/document based data. In many ways the textual warehouse serves the same function as a card catalogue in a library. In a large library there is a wide collection of knowledge and books. You would never want to walk into a library and look for a book by walking up and down the stacks of books and examining each book that was there. If you tried such an approach, you would be in the library for months at a time. Instead you go into the library and use the card catalogue to direct you to where you want to go. In doing so, you save endless amounts of time uselessly doing a search.
Libraries have known about and have used a textual warehouse for a long time now. In a library it is called a card catalog.

The textual warehouse is similar to a data warehouse except that it exists solely for the purpose of enabling the organization to find its text/document based data. In many ways the textual warehouse serves the same function as a card catalogue in a library. In a large library there is a wide collection of knowledge and books. You would never want to walk into a library and look for a book by walking up and down the stacks of books and examining each book that was there. If you tried such an approach, you would be in the library for months at a time. Instead you go into the library and use the card catalogue to direct you to where you want to go. In doing so, you save endless amounts of time uselessly doing a search.
Libraries have known about and have used a textual warehouse for a long time now. In a library it is called a card catalog.
The textual warehouse is similar to a data warehouse except that it exists solely for the purpose of enabling the organization to find its text/document based data. In many ways the textual warehouse serves the same function as a card catalogue in a library. In a large library there is a wide collection of knowledge and books. You would never want to walk into a library and look for a book by walking up and down the stacks of books and examining each book that was there. If you tried such an approach, you would be in the library for months at a time. Instead you go into the library and use the card catalogue to direct you to where you want to go. In doing so, you save endless amounts of time uselessly doing a search
.
Libraries have known about and have used a textual warehouse for a long time now. In a library it is called a card catalog.
In many ways, the textual warehouse is the analogical equivalent to the operational data repository
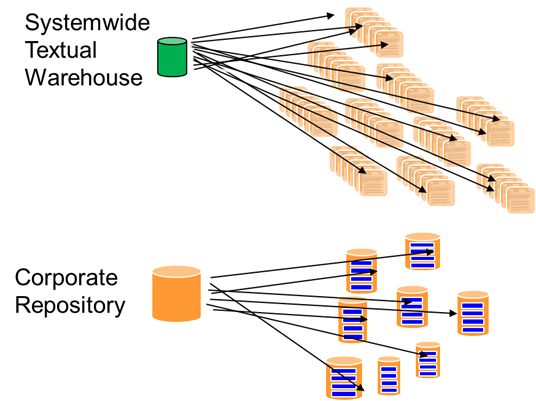
.
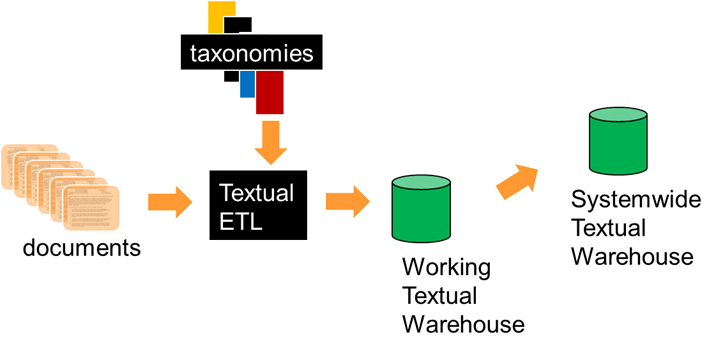
So what are the internal contents of the textual warehouse? There really are two types of content to the textual warehouse – mandated data and optional data.
MANDATED DATA
The mandated data in the textual warehouse looks like -
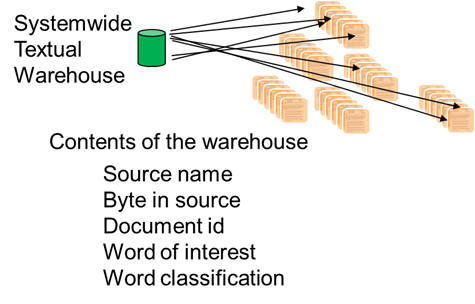
One type of mandated data is the source name. The source name is the name the system knows the document by. Another type of mandated data is the byte address of the word that is being referenced in the document. Another mandated type of data is the document id. This is the external name the document is known by, outside of the computer system. Next there is the word of interest, which is the referenced word. Then there is the word classification, which is the taxonomical reference to the word of interest.
These then are the types of data that every document must have in the textual warehouse.
OPTIONAL DATA
But you can include other types of data in the textual warehouse.
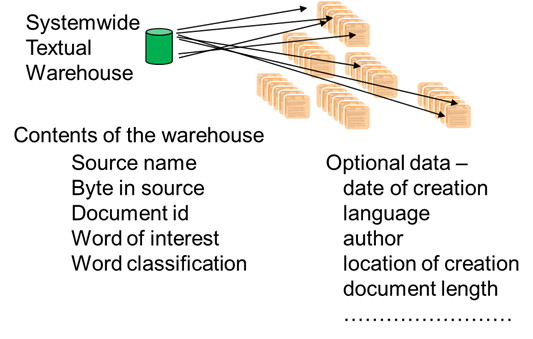
One type of mandated data is the source name. The source name is the name the system knows the document by. Another type of mandated data is the byte address of the word that is being referenced in the document. Another mandated type of data is the document id. This is the external name the document is known by, outside of the computer system. Next there is the word of interest, which is the referenced word. Then there is the word classification, which is the taxonomical reference to the word of interest.
These then are the types of data that every document must have in the textual warehouse.
OPTIONAL DATA
But you can include other types of data in the textual warehouse.
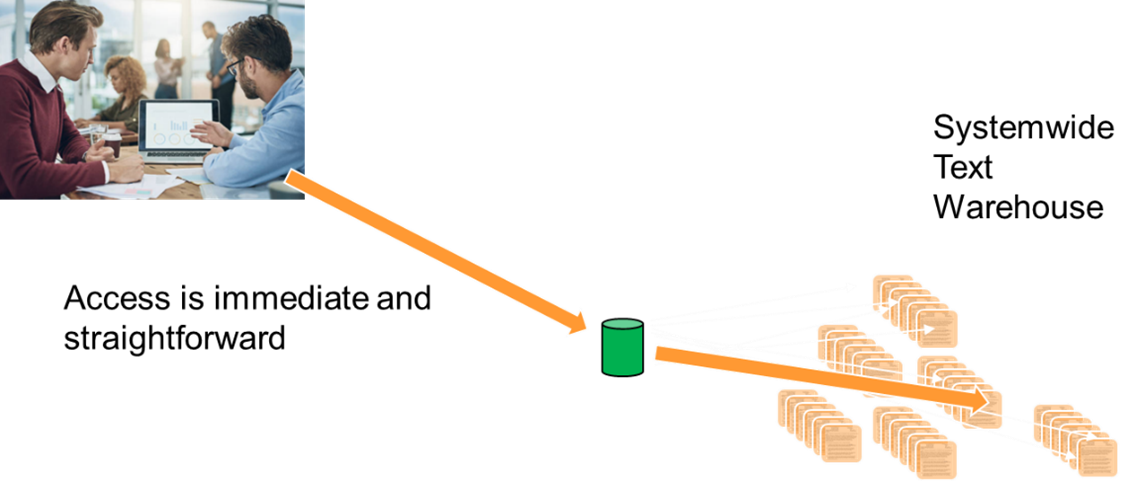
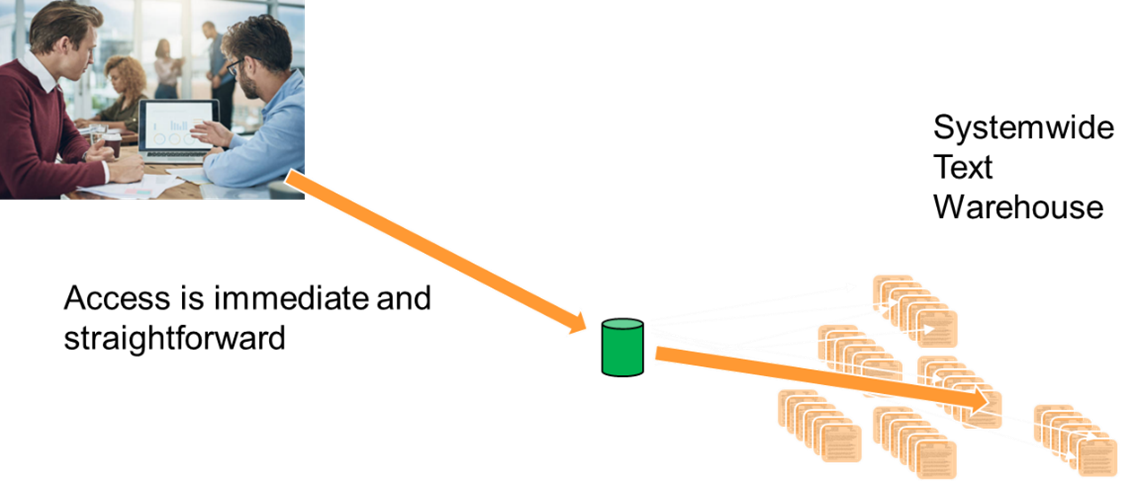
Now you can find documents and text easily through out your company easily and quickly.
Thanks. Textual warehouse seems to make sense for industries dependent on multipurpose knowledge text in digitized files, especially if must be retained for a long period of time, searched for audits, etc. and enable file retention policies governance + enforcement.
Files retention or deletion is more than admin housekeeping. Files retention also has other implications such as security risks or high storage costs.