
DATA ARCHITECTURE - EVOLUTION AND IMPLEMENTATION
A practical guide to modern data architecture

DATA ARCHITECTURE – EVOLUTION AND IMPLEMENTATION
By W H Inmon
Data architecture – or at least the early rudiments of data architecture – began when the very first programmer made a “data layout” for the magnetic files that were being created for simple applications. Life could not have been simpler for the data architect in this day and age.
SIMPLE ARCHITECTURE
Processing was done in a batch mode. Data was stored on magnetic tape files. The files of data were called master files. Reports were written that reflected processing. Life was simple.
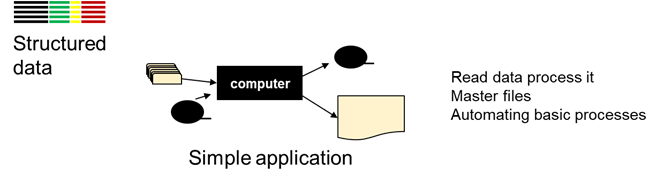
Soon there were lots of applications, performing all sorts of tasks.
One type of application that appeared was the transaction processing application. The transaction processing application opened the doors of the corporation to a new and important usage of the computer. Now bank teller processing, airlines reservation processing, ATM processing and a whole host of other processes became a reality and the computer further provided important and unique business value.
With the rise in applications (they came like weeds in the springtime) came the need to share data from one application to the next. Soon there was an innocent program called an “extract” program. The extract program took data from one application and placed it into another application. The extract program was a simple program.
THE SPIDER WEB ENVIRONMENT
In short order the combination of applications and extract programs produced an architecture which could be described as the “spider web environment”. The connection of all of the applications in a random fashion produced what appeared to be a spiders’ web.
The spiders web form of architecture had many problems. The primary problem was that the same element of data was placed in more than one place. In one place data element ABC had a value of 35. In another place data element ABC had a value of 50. And in yet another place data element ABC had a value of 600. The value of the data element was different in each place. The result was that no one actually knew the correct value of a data element.
Making decisions on data that could not be trusted was not a good way to run a business.

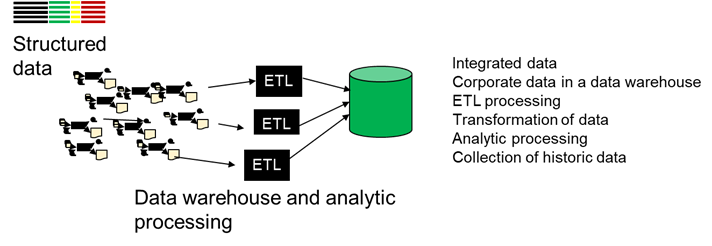
DATA WAREHOUSE ARCHITECTURE
In order to solve the problems of the spiders web environment, a data warehouse was built. The data warehouse was filled with application data that had been transformed through a process known as ETL – extract/transform/load.
Application data was read by an ETL program, transformed into an enterprise value, then placed into the data warehouse. In doing so, application data was transformed into enterprise data. Data across the corporation was now believable.
The data in the data warehouse represented data values across the enterprise. Another term for enterprise data was corporate data.
When built properly data from the data warehouse was reliable data. Data from the data warehouse – when built properly – was used by management with confidence.
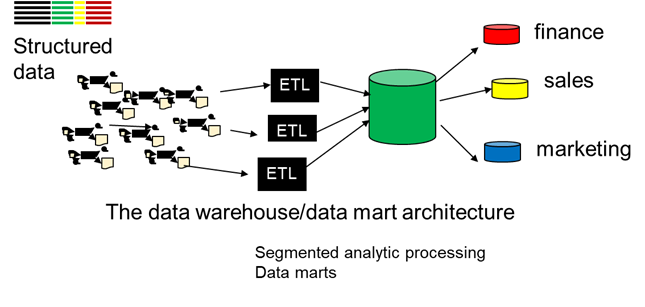
DATA WAREHOUSE/DATA MART
But soon different departments wanted their own interpretation of enterprise data. Soon marketing, sales, finance, accounting and other departments wanted their own customized version of data. Structures called data marts were built. The source of data for the data mart was the data warehouse.
As long as the data marts had the same common source of data – the data warehouse – there was always the possibility of reconcilability of data should there occur a contradiction of data between two different departments.
On occasion data marts were built directly from applications. This resulted in the unfortunate circumstance of the data mart being built on top of unbelievable data. When data marts were built on top of applications, reconcilability across data marts was not a possibility.
It was soon recognized that the proper source of data for the data mart was the data warehouse and only the data warehouse.
DATA VAULT
A further extension of the data warehouse concept evolved into a data vault. The data vault had several features beyond the data warehouse. The data vault offered a high degree of accountability of the data and the data vault offered structural flexibility.
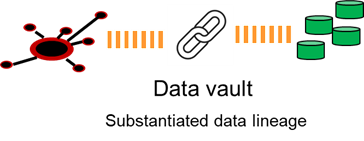
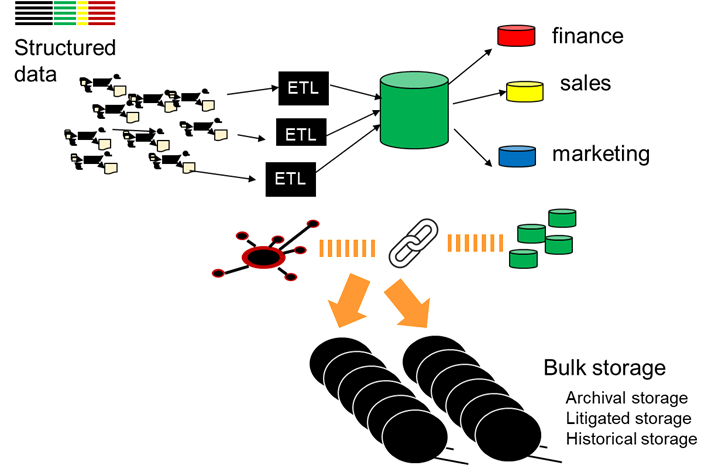
The architecture continued to grow. As time passed more and more data was accumulated. The accumulation of massive of amounts of data was both expensive to store and caused inefficiency of processing.
Over time much of the masses of data became dormant.
BULK STORAGE
In order to accommodate the collection of data that had a low probability of access and usage, bulk storage was used.
As long as data was active and frequently used, the data remained in the data warehouse and in other parts of the architecture, the application or the data vault.
But when the data no longer was actively being used, the data was moved to bulk storage.
The movement of data to bulk storage did not mean that the data could not be retrieved and used electronically. Instead, bulk storage data could be used electronically, but at a slow speed of access.
Bulk storage of data was less expensive than the storage of data on high performance storage. In addition, the removal of dormant data from the existing architecture meant that processing against current valued data could be done efficiently.
ENTER TEXTUAL DATA
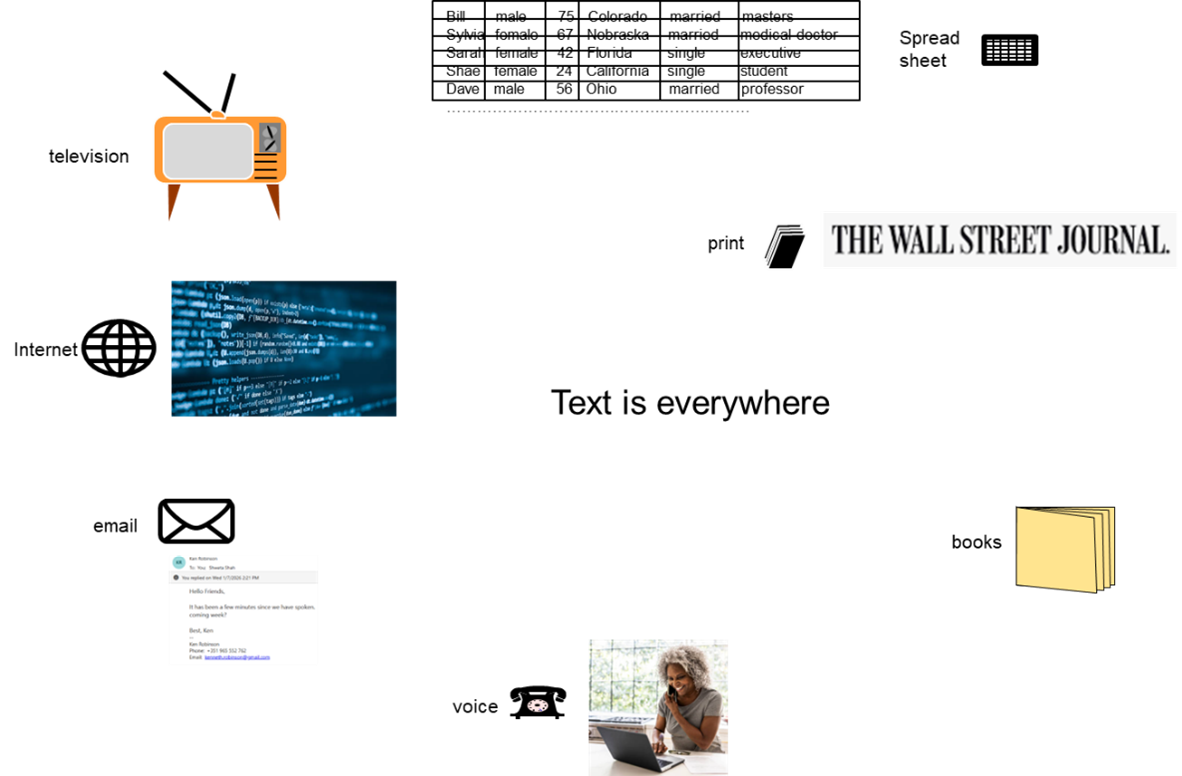
At the same time that the classical data architecture was evolving, it began to be recognized that data existed in other than a structured format.
It was recognized that important data also resided in a textual format.
There were indeed many sources of textual data.
There was –
Television
Spreadsheets
Books/newspapers/magazines
Internet
Contracts
And many more sources.
TEXTUAL CHALLENGES
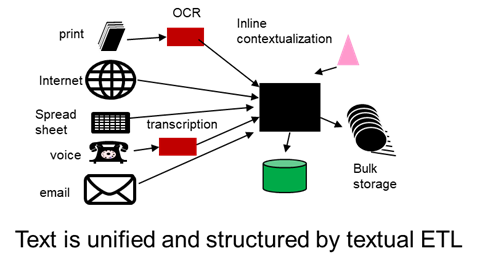
Text presented a special challenge to the data architect. In addition to being widely scattered, text required both text and context in order to be meaningful. The very format of text – unstructured data – did not fit the classical structured format of a data base.
There appeared technology known as textual ETL that allowed text to be captured, contextualized, and placed into a structured format.
Once text could be placed into a structured format, the textual data could be then juxtaposed against classical structured data. In doing so powerful analytics could be created.
TEXTUAL ETL
In addition, when text became structured, text could take advantage of the tools of analytics that already existed for structured data.
At this point both structured data and textual data could be placed into an architecture.
KEYS AND ATTRIBUTES
One of the perplexing problems of trying to mix structured data and text together is the fact that structured data is full of keys and attributes, while textual data essentially contains no keys or attributes. This fact makes mixing the two types of data together difficult.
There are – of course – other factors that separate structured data and textual data. One of those factors is that structured data has its context explicitly defined. Structured data context appears in the form of data base names, data element names, and so forth. The context of structured data is created as an act of the definition of the data base.
On the other hand, the context of text is derived from the text itself –
The fire was hot and it cooked the bacon.
He pulled the gun and fired.
My boss got really made and fired me.

Despite the fundamental differences between structured data and textual data, there was and is great advantage to capturing, structuring and analyzing both kinds of data.

THE DATA LAKE
The vendors of the world saw that handling both structured data and unstructured data had great value. The vendors of the world proposed an architectural structure called a data lake. The data lake architects called for the placement of the different kinds of data to be placed in a common pool called a data lake.
The data lake did not call for the integration of data. In a data lake, you simply take some data and throw it into a pool and hope that someone can make some sense of it. In short order the data lake turned into a data swamp. The data lake/data swamp was a disaster as an architectural entity

.Despite the amateurish efforts of the vendors at producing an architecture that combined both structured and textual data, the worlds of structured data and text continued to merge

.One of the interesting phenomena of the merger of data from the two worlds is the data that managed to cross the boundaries – from structured to text and from text to structured.
The ability to have data cross these boundaries did not occur frequently. But when the crossing became possible, whole new opportunities for analytical processing opened up.
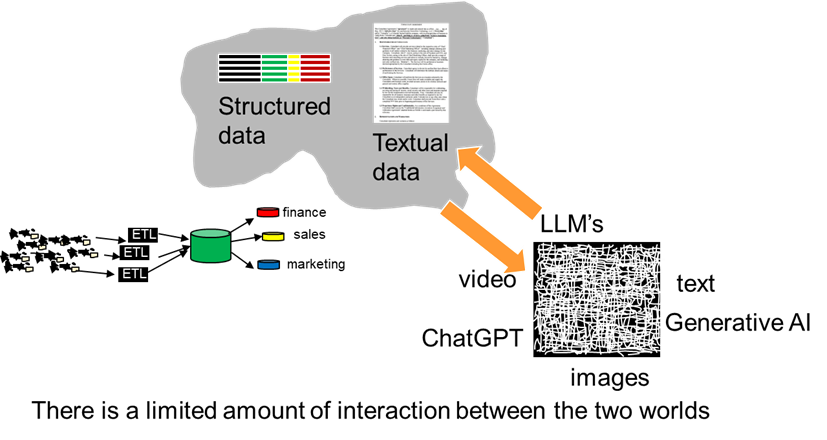
TODAY’S DATA ARCHITECTURE
From an architectural standpoint, the different architectures looks like -
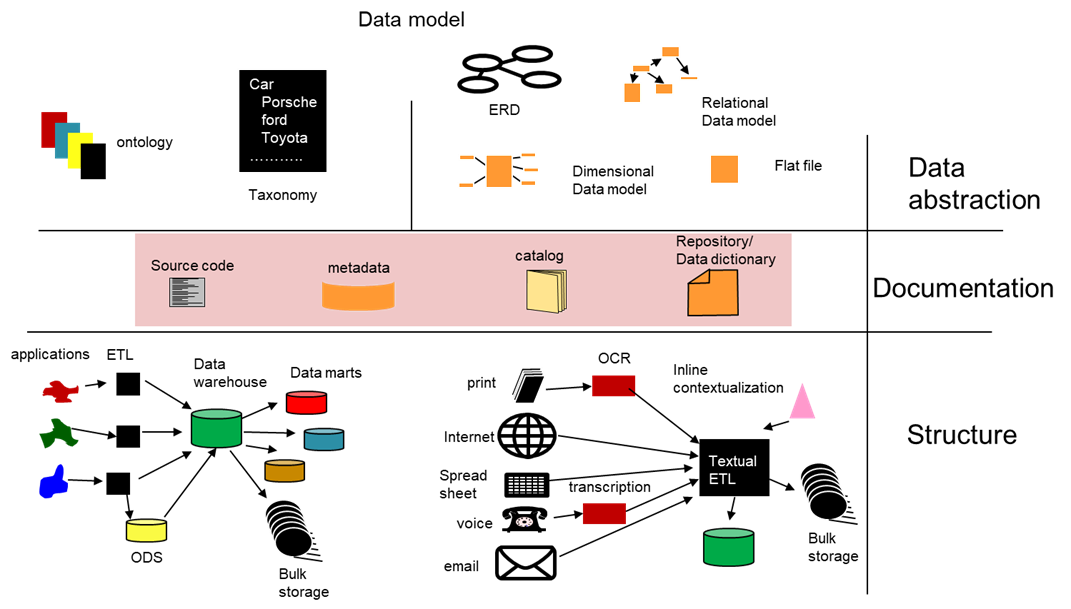
The architectural rendition can be divided into three distinct layers –
Data abstraction
Documentation
Structure
The types of data can be divided into structured data and textual data. There is a different architectural structure for each type of data.
The structured data abstraction consists of –
Entity relationship diagrams – ERD’s
The relational model
The dimensional data model
Flat files
The textual abstraction of data consists of –
Ontologies
Taxonomies
Documentation exists in many forms such as –
Repositories
Catalogs
Data dictionaries
Key word indexes
Metadata
The structure of data consists of –
Raw data
ETL and textual ETL
Bulk data
Data warehouses
Data marts
Operational data stores – ODS
The rendition of data that is presented here in no way represents what data architecture will look like ten years from now.
Data architecture is like a flowing river – ever evolving, ever changing. The only thing that is sure is that data architecture ten years from now will be different.
Some books you may enjoy –
TURNING TEXT INTO GOLD, by Ranjeet Srivastava and Bill Inmon, Technics Publications
A compendium of the technology needed to turn raw text into a standard data base
DATA ARCHITECTURE – BUILDING THE FOUNDATION, by Dave Rapien and Bill Inmon, Technics Publications
What is needed to build a firm foundation of data beneath AI
STONE TO SILICON – A HISTORY OF TECHNOLOGY AND COMPUTING, by Roger Whatley and Bill Inmon, Technics Publications
A practitioners story of the evolution of high tech, told by practitioners
Do I finally get to comment? It seems that it's getting harder and harder to comment or do anything else online, i.e., 'You have to know before you know'. Think about it. ...Secondly, my title as of 2020, 'Certified FOREST RIM® Textual ETL™ & Data Analyst', might have already been 'obsolete', maybe, by 2014! ...Thirdly, this is an interesting read, tracing the evolution of data architecture from SIMPLE ARCHITECTURE to DATA WAREHOUSE to DATA VAULT ('Lest we forget!') to TODAY’S DATA ARCHITECTURE and points in between (and B-E-Y-O-N-D . . .).
I had a removable hard disk when I was 21. Forty MBs. It was exceptional but not exactly uncommon. I worked on an ICL 1900 and a Univac 1100. Ancient, man!