
IN THE BEGINNING... A BRIEF HISTORY OF COMPUTING
From counting on fingers to AI, computing has advanced at a ,eteoric pace

IN THE BEGINNING…
By W H Inmon and Ole Olesen-Bagneux
The origins of computing go back to the day and age where men and women counted on their fingers of their hands and their toes.
A cavewoman would see her husband coming and ask how many fish he had caught. He would hold up two fingers and the cavewoman would know that there were two fish that were coming.
From those simple, humble beginnings arose, over the dawn of history, todays massively fast, massively powerful, massively versatile computing environment.
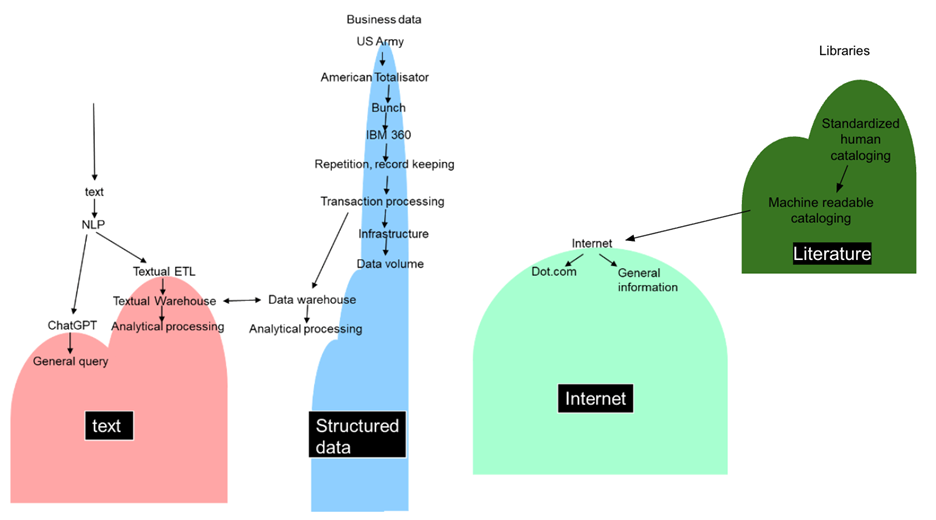
While there were many steps and improvements in the process of computing throughout the ages, the first recognizable, tangible computer was commissioned by the Us Army as a sophisticated calculation machine. The first recognizable, functional computer was designed to enhance the speed and accuracy of calculations needed by the US army in the 1940’s WWII era.
After the end of WWII, the organization that ran the horse racetracks in the US recognized a need for fast calculation of lots of data. This fast calculation ensured that the odds of a horse winning or losing according to the betting pools at the racetrack was done accurately. American Totalisator was the first major step of the computer away from military usage. With the movement of the computer from military to civilian usage, the management of betting on horse races ushered in the usage of the computer to business and the everyday man.
At this point in the life of the computer, the computer was almost exclusively a calculation machine. The intent and value of the computer was in its ability to perform quickly and accurately mathematical calculations.
Into this market entered IBM and the Bunch – Burroughs, Univac, NCR, CDC, and Honeywell. These early computers started to push the boundaries of computing away from pure calculation to more general purpose data processing. In this era it was found that the computer was much more versatile than a large and complex calculator. Now logic, non mathematical data, and complex algorithms could be performed by the computer, pushing computer technology to becoming what is in our era considered its natural state: A medium not only powered by electricity, like the telegraph, telephone and television, but a medium through which you could act: a digital medium, capable of executing human decision making – a computer.
At this point in time in the evolution of the computer, each computer required its own unique operating system. Programs and data were not easily transferable from one computer to another. Merely using the computer required that each computer have its own unique, complex, handcrafted operating system.
Each computer was an island unto itself. Transport of data and programs from one computer to the next was not a possibility when the computer operated in this manner.
IBM recognized the opportunity that was presented. What was needed was transferability of programs and data from one computer to the next. IBM gambled on being able to solve this need and built the model 360 line of computers. The model 360 computer line transformed the computing industry. With the advances made by IBM, now programs and data were easily transferable from one computer to the next.
IBM soon began to dominate the commercial computer marketplace with its 360 line of computing.
The early commercial applications for computers were primarily applications of the computer that did rote, repetitive work. The computer assisted corporations by minimizing the mandate for workers to sit and do the same task endlessly. And there was great business value in the alleviation of business doing rote tasks
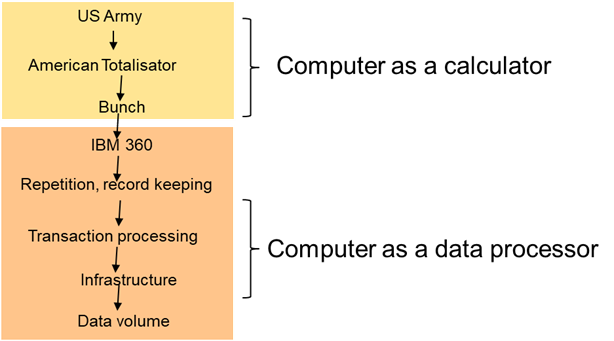
.However, a much greater business value was unlocked by the computer being able to do transaction processing. By merging the capabilities of a computer’s data base management system – dbms - with a teleprocessing monitor, online, up to the second transaction response time became a reality. In this way the human activity performed by unique computers suddenly morphed, and the power of human decision making was exponentially enforced with computers now linked to each other in what can be considered a network.
Commercial transaction processing opened up a whole new world of business activities that heretofore was not a possibility. With transaction processing came the ATM machine, airlines reservations, and bank teller support. And that was just the tip of the iceberg when it came to the ways business used the transaction processing capabilities of the computer. With transaction processing the computer went from something interesting to have in the corporation to an essential component of day to business activity in the corporation. Transaction response time and availability began to be a standard part of the businessperson’s vocabulary.
When the computer failed or had a problem – response time got slow or the system became unavailable – the business and its customers directly suffered.
With online transaction processing, the computer became an essential component of the business.
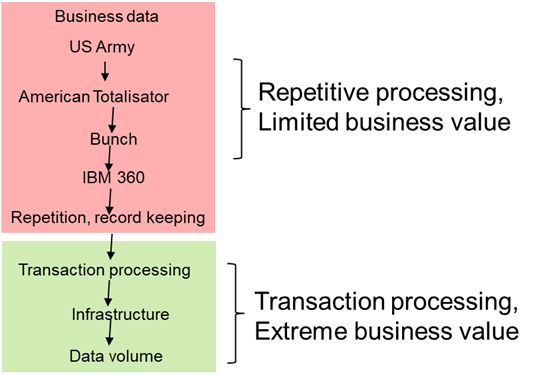
Soon corporations everywhere were doing transaction processing. Applications sprang up like weeds in the springtime. And with this explosion in applications there came another problem. The problem was not that data was not available. The problem was that data was available but was not believable. With multiple sources of truth – what was the truth?
The same data appeared in five different applications where there was a different value in each application. No one knew what data to believe. In one place revenue was $10,000. In another place revenue was $5. In another place revenue was $100,000. Making corporate decisions on unreliable data was a fool’s game.
Into this fray came the data warehouse. The advent of the data warehouse set the stage for an entirely different kind of processing – analytical processing. In analytical processing people did not do transaction processing. Instead, people gathered their data and looked at the data analytically, looking for trends, KPI’s and other important measurements of the business of the corporation.
In many ways, analytical processing was far, far different from transaction processing.
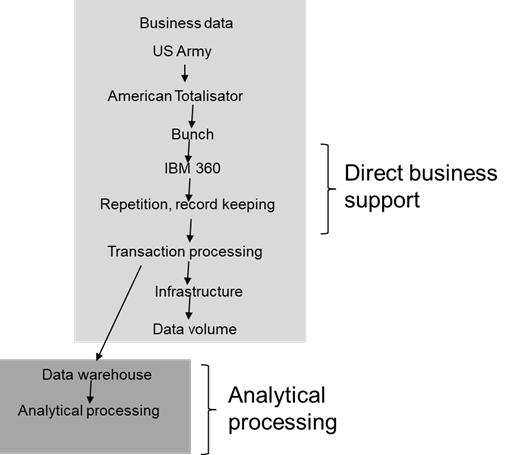
Both transaction processing and analytical processing were internal to the enterprise. The data and the processing for both of these environments existed almost exclusively inside the walls of the corporation.
But there appeared at this time an external method of computing, a method of computing that existed well beyond the walls of the corporation. Next came the Internet, pushing the idea of connecting computers further again, with yet another layer of exponential decision power allowed by computers.
The Internet existed well beyond the walls of the corporation. The Internet was external to internal processing and did not live within the walls of the corporation.
In many ways the Internet was a data base. However, the Internet was an uncontrolled, everyone do their own thing data base. There simply were very few guidelines or restrictions as to what could go onto the Internet. Unlike the data bases found within the walls of the corporation, there were very few rules and restrictions on the Internet and its contents. It is instructive that the first widespread application that helped popularize the Internet in its earliest days was pornography. But shortly there was far more on the Internet than pornography.
External data – the Internet – was free from the restrictions and discipline of internal, enterprise data. No longer was the IT department needed or even wanted. The personal computer enabled the advent of the Internet. Once only large corporations and large departments within the organization had their own computers. With the personal computer anyone could afford to own and use the computer. The end user was free to find anything he/she wanted and to put anything on the Internet (with only the barest of legal restrictions.)
Facilitating the usage of the personal computer was the ubiquitous spreadsheet. With the spreadsheet anyone could start to place data on the computer and analyze it. The IT department was not needed in the face of the spreadsheet.
People found that with the Internet they could reach and have contact with audiences in places never before possible.
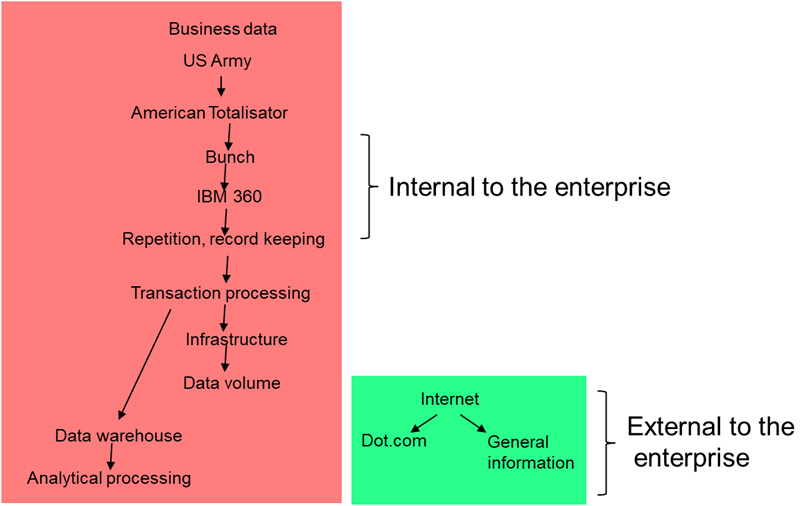
Soon, the internet reality and enterprise reality would blend in a surprising, yet logical way.
The world of enterprise computing is dominated by what is called “structured data”. Structured data is data whose form appears repeatedly but whose content varies. For example, the daily transactions created by sales made at Wal Mart all have the same structure but each record of a sale has different content. Structured data is organized in a form that is optimal for the processing of a computer. Structured data fits comfortably inside a standard data base management system.
Much corporate business is conducted through structured data.
However, structured data actually makes up only a small amount of the data found in the corporation. In most corporations 85% to 95% of the data flowing through the corporation is in the form of text. Text, unfortunately, fits very uncomfortably inside a standard data base management system. Text is said to be unstructured data. As such the computer has always had a difficult time dealing with the unstructured format of text.
But text comes from many places – not just the corporation (although text certainly is found there.) The vast majority of the Internet resides in the form of text. There is a wealth of text found in the Internet.
In order to process the text found on the Internet and in the corporation, technology called textual ETL was created. With textual ETL you could now start to access and analyze text and move that text to the data warehouses of the world.
In addition to enabling the processing of text, textual ETL made it possible to build a textual warehouse. With the textual warehouse, whole new vistas of analytical processing were possible.
In addition, text from the Internet became available for analytical processing. And, with textual ETL, text from the structured environment could be intermixed with text from the Internet.
But a different kind of textual processing became available as well. ChatGPT introduced analytic processing with a natural language interface. The ability of people to talk with the computer removed the technical barrier that was once there.
Now the world of technology was open to everyone, no technical barriers required
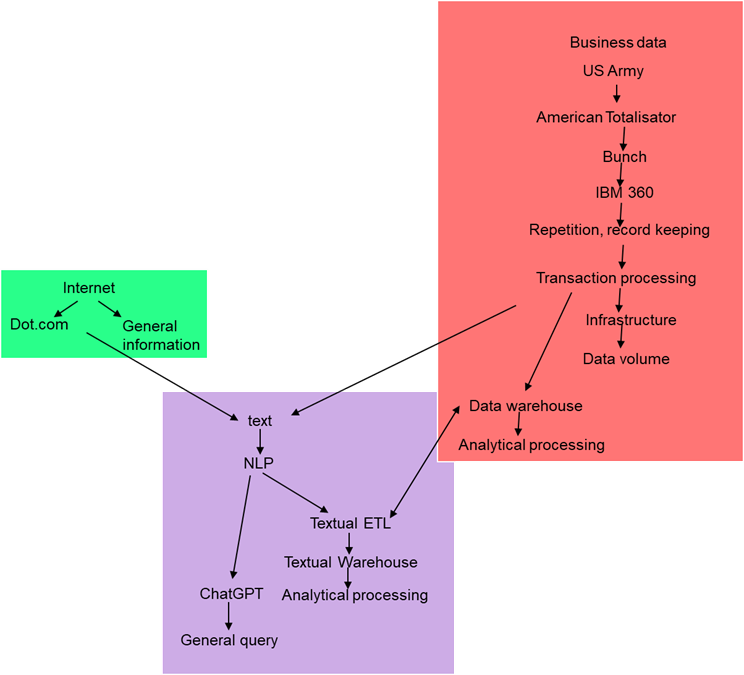
.These different venues of processing – the structured world, the Internet word, and the world of text – encompassed very different audiences in very different ways. The people that actively used these environments were very different. The world of structured data was inhabited by business people making business decisions. The world of the Internet was inhabited by a much larger audience – the common person and the business person – both small business and large business. The Internet contained web sites where all sorts of products and all sorts of services could be entertained.
However, the world of the Internet did require a modicum of computer skills. The level of skill required for access to the computer by the Internet was very small compared to the skill sets required for maneuvering through the corporate environment. But with ChatGPT the level of skill required to access the computer dropped to practically zero.
With ChatGPT practically anyone could start to access and use data found on the computer.
What developed was a three channeled approach – there were business users of the computer, there were Internet users of the computer, and there were the everyman users of the computer.
These three audiences did have some degree of intersection. A person could use the computer at work, go home and access the Internet, then use the ChatGPT facilities in order to access further information. In that regard, there were some intersections of the audiences of the three different modes of computing.
Nevertheless, the audiences still remained separate and apart, for the most part.
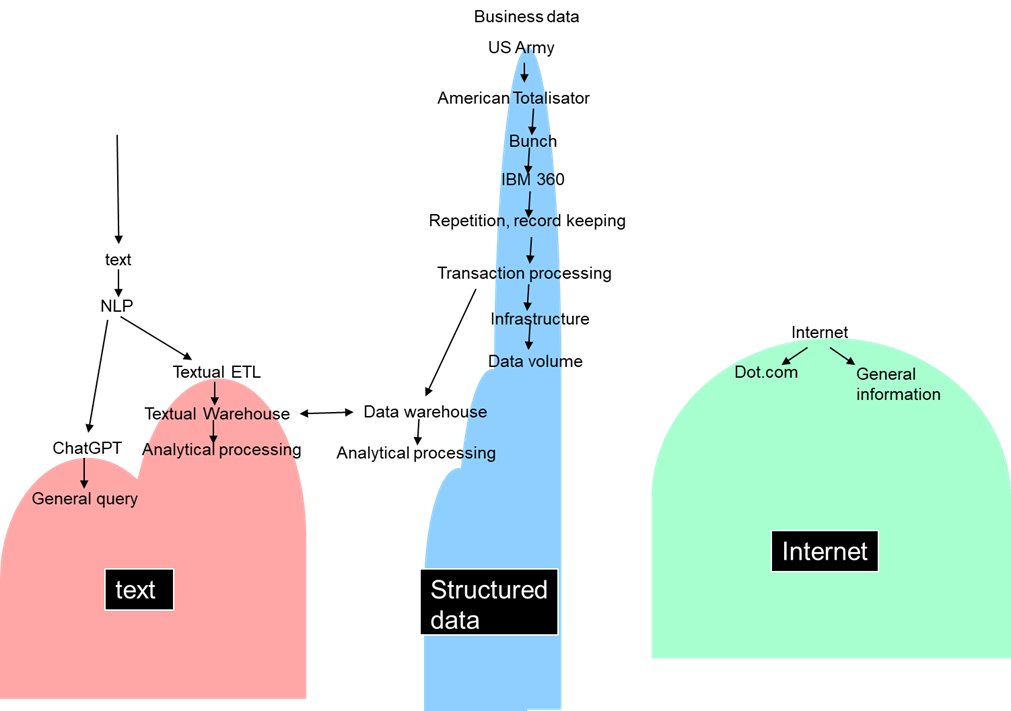
It is of interest to note that text comes from both the Internet environment and the business environment. From the standpoint of the environments being able to be intermixed, text from both of the environments can be freely mixed.
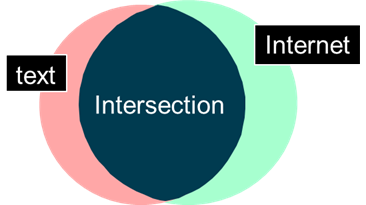
Over time the different strains of computing and data have become quite intermixed. The result today is a very confused mixture and blending of data.
What is needed is a comprehensive, carefully constructed architecture of data in order to make sense of and manage proactively the data and computer environment facing the end user today.
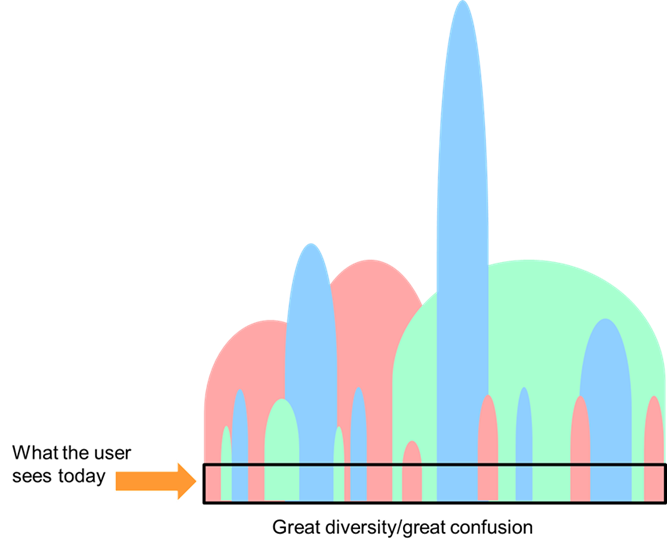
Without a well established and comprehensive architecture, the end user will be lost in the jungle of data and conflicting and inconsistent information that confronts the end user today.
Some of the elements (but hardly all) of a comprehensive data architecture include the elements of –
Believability of the data
How complete is the data
How accurate is the data
How current is the data
How reliable is textual data
Identification of the source of the data
What is the source
What is the lineage of the data
What modifications have been made to the data
Metadata
What does the data mean
What does the data not mean
How does the data relate to other data
What is the purpose of the metadata itself – what capability does it support?
Where is that purpose carried out - what metadata repository)?
Why is this metadata shaped differently than metadata from other repositories?
How does metadata for structured repositories differ from metadata from unstructured repositories?
Data model
What full commonality do different types of data share
What partial commonalities do different types of data share
What does the structure of the data look like
What does the structured data model look like
What does the textual data model look like
What are the different types of data
How does textual data relate to structured data
What types of data other than textual and structured data are there
And these are merely the SIMPLE aspects of a comprehensive data architecture. It is recognized that there are many more aspects of the architecture that are needed used as a guideline in understanding today’s data.
We live in an era that has turned the internal hierarchy of data upside down. It used to be so, that structured data was at the core of the data management and data engineering profession. The textual warehouse is a vision to allow for the creation analytical processing of unstructured data, because the vast amount of data in companies is in the form of text. It a fundamentally powerful idea. And the textual warehouse came into being with significant outcomes as a result for those that were capable of using it. With the rise of ChatGPT, the technical boundaries of analytical harnessing of unstructured data have been removed. ChatGPT does not replace the textual warehouse – as it is two distinct technologies – it merely opens a frictionless window for end users to engage with text – and data. Therefore, managing text, and understanding the analytical potential of unstructured data altogether is now at the core of data management.
What this means is as already stated an open question.
A literature dimension: the digitization of knowledge organization in libraries
Something happened next to the evolution of computers for military and civil enterprise use, and finally for end users in their private life through internet. That was the digitization of knowledge organization in libraries.
Throughout the second half of the 19th century, standardized, mechanical approaches to the intellectual organization of literature had pushed the US library sector forward in its mission to educate and inform all citizens and society at large. These processes were mostly carried out by humans, but the evolution of numerical classification systems and industrial production of furniture and equipment help bring about a standardization of the knowledge organization performed in libraries. This allowed for literature to not sit in one designated physical place (one particular shelf), but in an abstract location (e.g. 510 for Mathematics in Dewey Decimal Classification). This brought elasticity and flexibility to knowledge organizational principles carried out in libraries and created an academic culture of the organizing and retrieval of literature, through standardized catalogs.
With the advent of computers, computer scientists in the library sector pushed forward to make cataloging even more powerful. A notable person was the programmer Henriette Avram, creator of the MARC format, and a distinguished employee at the Library of Congress. The MARC format turned physical card catalogs into a computerized catalog system and thereby made it possible for the library sector to keep up with the increased production pace of fiction and nonfiction literature. It scaled cataloging by eliminating the manual effort of coordinating physical catalogs across great distances and help speed up discoverability of new literature. It is not a stretch to claim, that Avram’s invention helped save the literary heritage of the world amidst the explosion of new media.
However, there was also a second, later effect of the computerization of cataloging. The discipline of putting computers at the center of knowledge organization of literature brought about principles that suddenly turned useful in a new, unforeseen reality: The internet. The methodologies developed in the intersection of academic librarianship and computer science helped create structured approaches such as Dublin Core, RDF. It further helped bring about ontologies materialized in knowledge graphs for powerful search engines.
The methods in this discipline, now primarily known as information science, can further help standardize and structure the blurred reality end users are experiencing in the great diversity and great confusion when interacting with text through the internet.
Recently the book STONE TO SILICON: THE HISTORY OF TECHNOLOGY AND COMPUTING, Technics Publications was released. This material has been adapted from the book. For a much more comprehensive and complete description of the evolution of computer technology, please refer to this book.
Some books you may enjoy –
STONE TO SILICON: A HISTORY OF TECHNOLOGY AND COMPUTING, W H Inmon and Dr Roger Whatley, Technics Publications
TURNING TEXT INTO GOLD, W H Inmon and Ranjeet Srivastava, Technics Publications
BUILDING THE TEXTUAL WAREHOUSE, W H Inmon and Ranjeet Srivastava, Technics Publications
DATA ARCHITECTURE: BUILDING THE FOUNDATION, W H Inmon and Dave Rapien, Technics Publications
FUNDAMENTALS OF METADATA MANAGEMENT, Ole Olesen-Bagneux, Oreilly Publications
THE ENTERPRISE DATA CATALOG, Ole Olesen-Bagneux, Oreilly Publications
All books are available on Amazon.com.
Absolutely amazing historical journey.
Thank you, Bill!
Thank you. I appreciate tech content written like a story because stories are memorable.