
MASTERING UNSTRUCTURED DATA - DATA MODELS AND DATA STRUCTURES
Turning text into business value

MASTERING UNSTRUCTURED DATA – DATA MODELS AND DATA STRUCTURES
By W H Inmon
How is it that humans come to grips with complexity? The classical and time honored approach to dealing with complexity is to –
Employ abstraction to determine the shape and structure of the object being analyzed
Look across the vistas of the complex landscape
Break a complex problem down into its component pieces
As an example of dealing with complexity, consider a ship on the sea. There are many factors that affect the safety of the ship and the voyage it is going on. There are only landmarks on the sea when the ship nears the coast. In the middle of the ocean there are no hard and fast landmarks. So how does the ship know what the proper setting of the rudder is to be? The captain of the ship relies on his/her compass

.COMPLEX WORLDS
There is hardly a more complex world than today’s IT environment. The IT environment has been evolving for half a century or more now and is going to continue to evolve. What was once fairly straightforward is anything but straightforward today. And the IT environment is full of seemingly unrelated and complex topics –
Legacy systems
AI
Venture capitalists
Chip vendors
Vendors that mislead their customers
Dashboards
And a host of other disciplines and technologies.
And IT is hardly the only world of complexity that there is. In another venue there is the world of text – unstructured information. There are news reports. There are newspapers. There are government reports. There are comic books. There is the Internet. And nobody seems to agree with anyone else.
If there ever was a world that was free form and complex, it would be the world of unstructured data and text.

THE STRUCTURED DATA MODEL
So what kind of compasses exist for these very different worlds? What is the compass for IT?
For IT there is the compass of the data model. The data model holds and structures the metadata that describes and defines the IT environment.
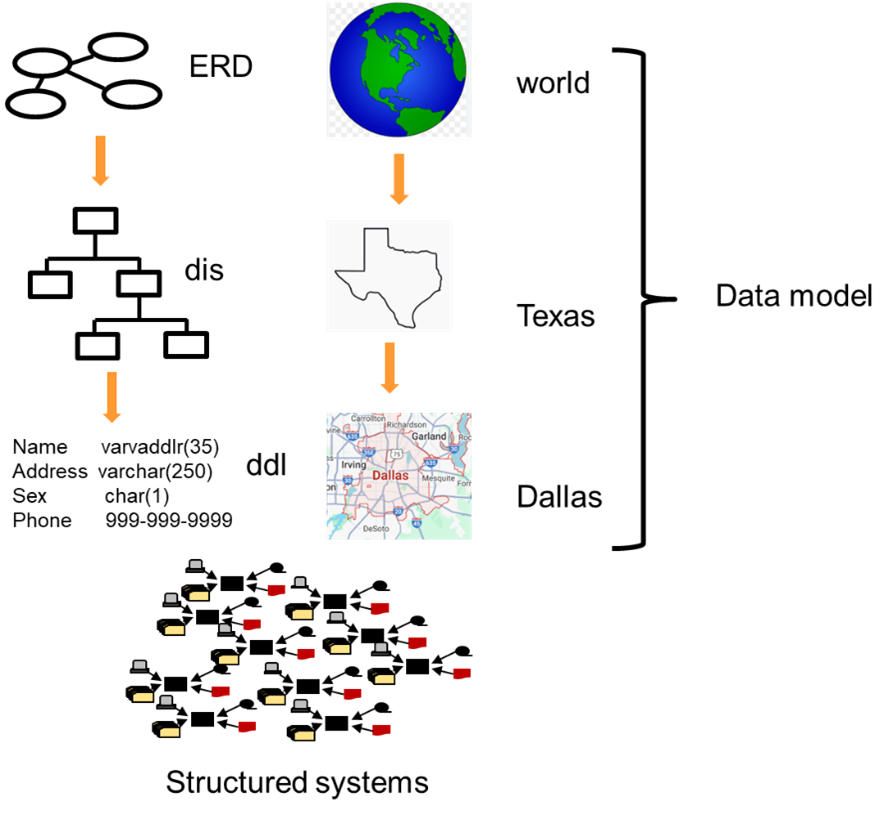
A classical data model exists at different levels of abstraction. The classical data model has a high level of abstraction called the ERD – entity relationship diagram. Each of the entities described in the ERD has a lower level of detail for each of the entities. This level is called the ‘dis” or data item set. In the mid level of the data model – the dis – data item set – level of the model - are found keys, attributes and relationships.
At the lowest level of the structured data model is found the place where the model is described to the dbms – data base management system. This is called the ddl – data definition language. Each of the levels of the data model are related to each other, in much the same way as the globe of the world relates to Texas, and Texas relates to the city of Dallas.
When the structured data model is created and maintained properly, it is a guideline to the labyrinth of IT.
THE TEXT MODEL
The world of unstructured data has its own model – a text model. The text model is the compass for unstructured data and text. The first issue of the text model is – what level of granularity does the text model exist at?
There are at least two levels of granularity of the text model – the chunk level and the word level. A chunk is a collection of text that contains words that form some kind of thought that has been expressed. The word level is the lowest level of granularity of the unstructured environment. Each of these levels of granularity have their own advantages and disadvantages.
Unstructured data at the chunk level is good for understanding the reliability and the veracity of the thought that is being expressed. Unstructured data at the word level expresses text and the lowest level of granularity. Words are good for simple contextualization, but not for complete expression of a thought.
In any case, both chunks and words require context in order to be meaningful. Text – in any form – without context is a pointless exercise. Text without context can even be dangerous.
A simple example of the need for context is the understanding of the word – “fire”. What does fire mean?
Fire can mean a flame, a conflagration. Fire can mean the pulling of the trigger of a loaded gun. Fire can mean the involuntary cessation of employment.
You do not know what the word fire means until you understand the context of fire.
And language is FULL of the need for context.
In everyday speech people take context for granted because that is a normal part of understanding language.

THE TEXT MODEL
The text model – the unstructured equivalent of the data model – is based on an ontology. An ontology is a vocabulary of words that reflects some discipline. The discipline can be broad or narrow. Typical disciplines that might be modelled might include medicine, legal, banking, telecommunications, military, and so forth.
The ontology consists of one or more taxonomies. A taxonomy is a vocabulary that relates to some one subject. The taxonomies in an ontology may or may not have an interrelationship between themselves.
For example, the ontology for medicine might contain taxonomies for such things as medications, diagnoses, oncology, dermatology, the ICU and so forth. The ontology for a bank might include such taxonomies as account management, loans, credit cards, savings, and so forth.
The taxonomy consists of two basic elements –
The word being examined (that is the focus of the taxonomy)
The context of the word
For example, the taxonomy for medicine might contain such things as –
Word – envarsus, context -medication
Word - blood pressure, context - vital sign
Word – milliliter, context – measurement
Word – blood, context – body fluid

MODEL DIFFERENCES
The data model and the text model both act as the compass for understanding their different environments. However, the data model and the text model are very different from each other. There are only casual similarities between the two model types, at best.

STRUCTURED DATA AND TEXT DIFFERENCES
There are some important and basic reasons why the two model types are so different. The primary root of the differences is housed in the fact that structured data and text and fundamentally different.

The primary way that structured data and text are different is the fact that structured data is dominated by keys and attributes. Structured data is made up of records of data. All the records of data in the same data base have the same structure. Only the value of data in each record is different.
Text on the other hand has very few – if any – keys or attributes. It is very unusual for a person to write an email –
“My social security number is – 123-45-6789.”
Of course, a person can write such a sentence. But it is unusual for that to happen. Instead, text is free form. People say what they need to say in order to communicate. It is really unusual for key data to appear in a text format.
When examining text and structured data, the very structure of the information is very different.

CONTEXT IN THE DIFFERENT ENVIRONMENTS
Another major difference between structured data and text is that of the existence and usage of context in each environment.
Both structured data and text require context. But context is derived and treated very differently in the two environments. In the case of structured data, context is determined at the moment that the data base is defined to the system. The developer identifies the data base and the keys and attributes of the data base at the moment of definition. And from that moment onward, the structured data is tagged with its context. Context is explicitly stated at the moment of creation of the structured data.
Textual data requires context as much as structured data. However, the context of text is determined within the actual text itself. People are used to determining the context of text as a natural part of speaking or writing. The contextualization of text occurs naturally, without conscious thought.
For example, when someone says –
“the fire is hot”
Fire is understood to mean a conflagration.
But when someone says –
“he pulled the trigger and the gun fired”
Fire is understood to mean the firing of a gun.
The context of the meaning of the word is buried in the complete collection of the text itself.
Both structured data and text require context. But con
text is derived and is understood entirely differently in both environments.

REPETITION OF DATA
Another major difference between the structured environment and the unstructured, textual environment is the repetition which occurs in the different environments.
Structured data is highly repetitive. When John Smith makes a purchase at WalMart, a record of the purchase is created. Then Mary Jones makes a purchase at WalMart and a record of that purchase is made as well. The record made for John and Mary is identical and repetitive. The only difference between the two records is the data that has been recorded. But the two transactions/purchases are highly repetitive.
In a days time there will be many such records written repetitively.
Text - on the other hand – is highly non repetitive.
Mack Wilson writes an email –
“I won’t be at the game tonight. My daughter is sick with measles.”
Mack may never write that same email again.
Structured data is highly repetitive and text data is highly random and non repetitive and this difference is another dividing line between the two environments.

STRUCTURING TEXT
In order for text to be subjected to analytical processing, text needs to be recast into a structured format. Modern analytical packages require that text be presented in a structured format. This is done by using textual ETL (TETL) to read the raw text and to produce a structured data base from the raw text that has been read.
The raw text that can be read is in many different formats, such as –
The Internet
Voice recordings
Spreadsheet
Or other sources of text.
The raw text is ingested and passed through TETL where it meets up with taxonomies that have been focused on the subject or discipline that is of interest. A structured data base is produced.
The transformation from raw text into a data base then is made by TETL.
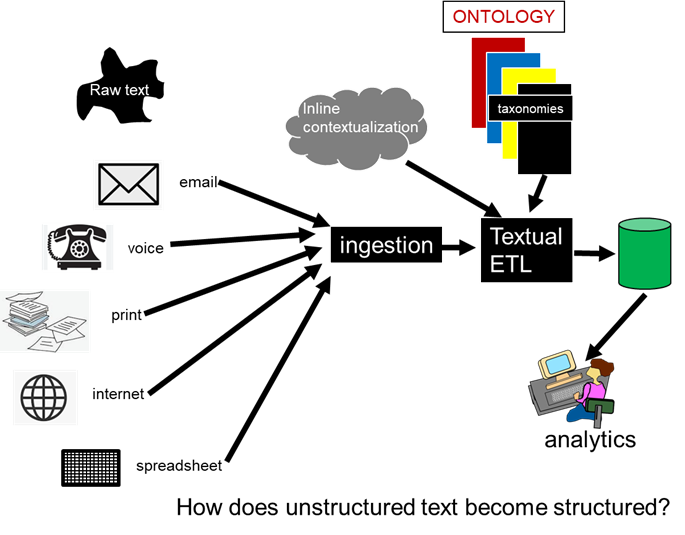
The taxonomy and the raw text are used as input to TETL. The raw text is scanned and it is determined if the word being examined is in a taxonomy. If not, nothing happens. But if the word being examined does reside in a taxonomy, the word and its context are placed into a data base.
The interaction between the taxonomy and the taxonomies found in the ontology are basic and simple, as depicted
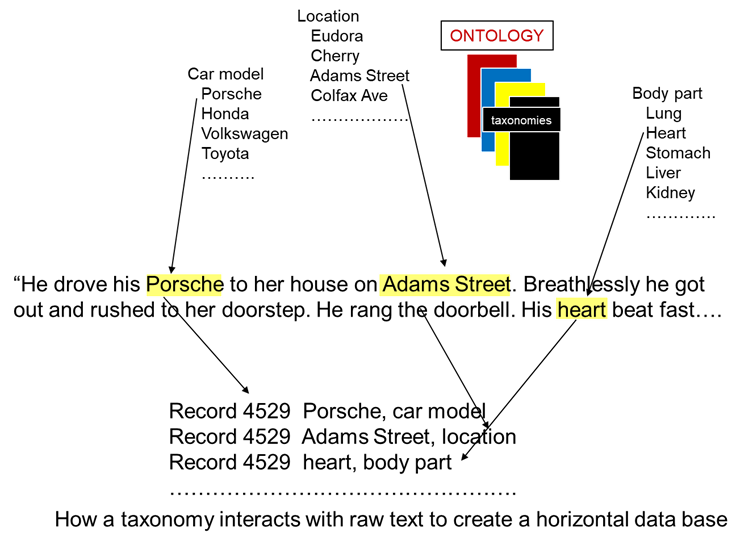
.As an example of raw text that can be turned into a data base, consider the following snippet of text that is taken from a medical record -

When the raw text is passed against the medical ontology and its many taxonomies, the following data base is produced –
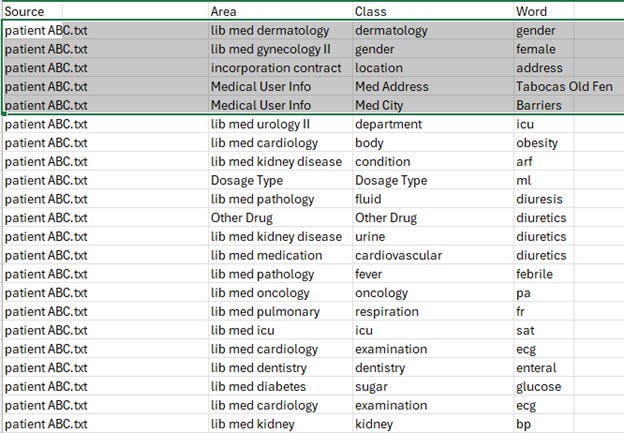
In the data base that has been produced there are two levels of context – class and area.
VERTICAL VERSUS HORIZONTAL STRUCTURING OF DATA
While the data base that is produced by TETL indeed is structured, the format of the textual data base is significantly different from the format of a structured data base.
A structured data is found to be in the format of a table. The structured formatting of a table can be called a vertical structuring of data. Each column heading identifies the context of the data base. In the “name” column of a structured data base will be found –
Bill
Sarah
Sylvia
And so forth
You will never find Taco or chile relleno of snow shovel or quarterback sneak in the name column of a structured data base.
The same goes for the column named “school”. In the school column you might find –
UCLA
Purdue
Harvard
You would never find Jim Thorpe or the Lusitania or tamales or leap frog in the school column.
The general demeanor of the structured data base is that the context of the data is vertical. The context heads the column and the column is then populated by instances of the context, all falling vertically from the column name.
Textual data base structure is the opposite of structured data base structure. Textual data bases are said to be formatted horizontally. Each row of data in a textually formatted data base consists of the instance of data and its context. The context describes the text in the same horizontal row. The text and its context are displayed in a row in a horizontal manner.
For example, there might be –
Instance – Porsche, context – car model
Instance – machaca, context – food
Instance – Joe Montana, Context – football player
And so forth
Looking down the context column vertically, there is no uniformity of the values in the column. The context of the data found there can represent can be anything.
The horizontal formatting of text is necessary given the random nature in which text appears. The occurrence of text appears in a random manner and the elements of context found in the context column are also random.
The structuring of structured data and text is both completed in a structured format. But the internal basic organization of the structured format compared to the text format is very, very different.

STATIC DBMS STRUCTURES
In most dbms that service structured systems, the structure of the data is reflected in the data structure of the dbms itself. The structural representation of the data in a structured data format has the effect of locking the structure into the data base. In other words, the structured representation of the structure of the data is static. Once the structure of the data has been locked into the dbms, It is not easy or pleasant to modify.
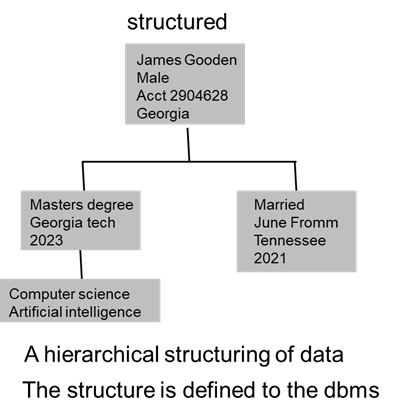
As an example of structured data being cast into the form of the dbms, consider the following diagram.
In the diagram there is a hierarchical representation of data. Th dbms is designed to house and handle hierarchical data. A man – James Gooden – is shown to be in the parent location of the structure. There is some basic information about the man in the parent grouping of the data –
His gender
His account number
The state in which he resides
Then it is seen that James Gooden has a masters degree from Georgia Tech. He got his degrees in 2023. There may be multiple occurrences of education as well. Only the latest occurrence of data is shown in the diagram. James also has a bachelor’s degree from Florida State in engineering as well but it is not shown in the diagram..
James Master’s degree was in computer science and psychology. And James is married to June (nee) Fromm who is from Tennessee.
The structure of the data is defined to the data base management system in a hierarchical structure.
Because the structure of the data is defined to the dbms, it is static. It is not particularly easy for the analyst to add the parents of James, the hobbies of James, the synagogue that James attends, and so forth. Once the basic structure is defined to the data, it is static and not easy to alter.
A DYNAMIC STRUCTURING OF DATA
Textual data is not static at all. Textual data is dynamic. Textual data structures must be dynamic because the data structures that occur in text are VERY fluid and very dynamic. And text as it appears in writing or speech is certainly free form.
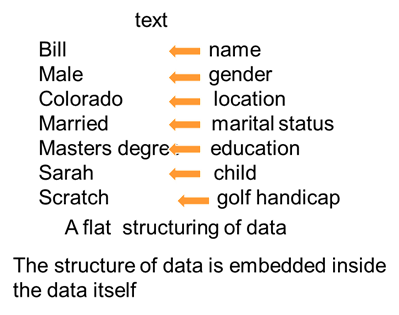
As an example of the fluid structure of textual data, consider the simple data base shown in the following diagram.
In this simple data base, it is seen that the name of the person mentioned in the text is Bill. Bill is a male. Bill lives in Colorado. Bill is married, and so forth. This record of Bill was created by the examination of a textual description.
The contents of the record of Bill depend entirely on the text that is generating the data. The records created for one conversation may mention one set of things. Another record of another conversation may mention an entirely different set of things.
The discussion of Kei Lou may mention her boyfriends, her pet cat, and her favorite foods.
The contents of what ends up in the data base depends entirely on the text as it is spoken or written.
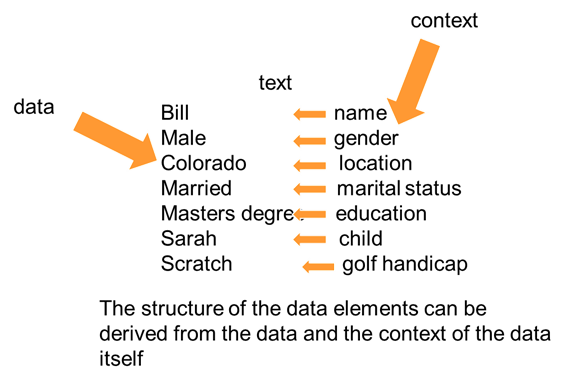
WORDS AND CONTEXT
There are two components of textual structure that are found in the simple data base – the word that has been encountered and the context of that word.
THE POWER OF DYNAMIC STRUCTURING OF TEXT
It is not obvious that there is great power in the structuring of data this way. The only obvious power is that the structuring of textual data as has been discussed fits the free form style of the way that text is created.
But there are some very important other properties of this dynamic structuring of data. The horizontal structuring of textual data allows ANY relationship of data to be depicted. Unlike a vertical horizontal structuring of data that is found with structured data, the vertical structuring of data is dynamic, not static.
Stated differently, the static structuring of data is only able to depict the data as it has been cast at the moment of definition. But the dynamic structuring of data is capable of depicting ANY structure of data.
The textual data structures that can be formed depend only on the data that has been captured. In other words, ANY structuring of textual data can be accommodated. Which of course fits nicely with text because there is no prescribed structure of data when conversation occurs. A person can write anything they want in an email. Or say anything they want in a telephone conversation.
A SMALL DATA BASE
In order to demonstrate the power of dynamically created relationships of data, consider the following small data base.
The small data base has been created from some basic medical records. The (simplified) medical records contain information about –
The person being documented
The drugs the person takes
The gender of the person
The location of the person.
Of course, the medical records may contain a lot of other information. But for the purpose of this example, only the data that has been described will be considered.
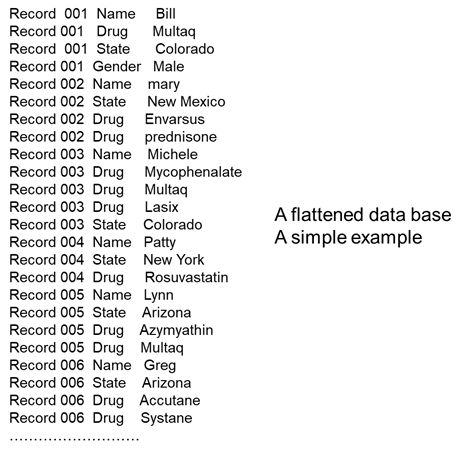
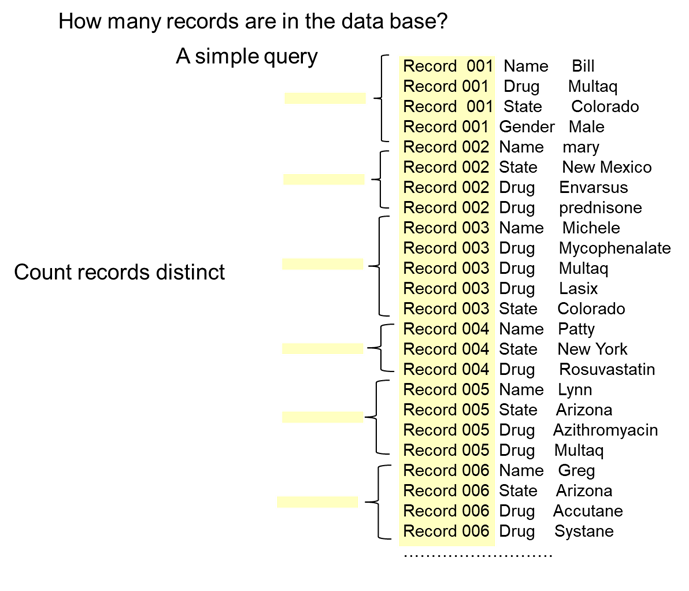
The first kind of simple query that can be examined is – how many records are in the data base.
This query can be accommodated by looking at the record columns and counting distinct rows. In this case there are six unique record types that can be found in the data base.
This however is a simple query.
Much more sophisticated queries can be accommodated
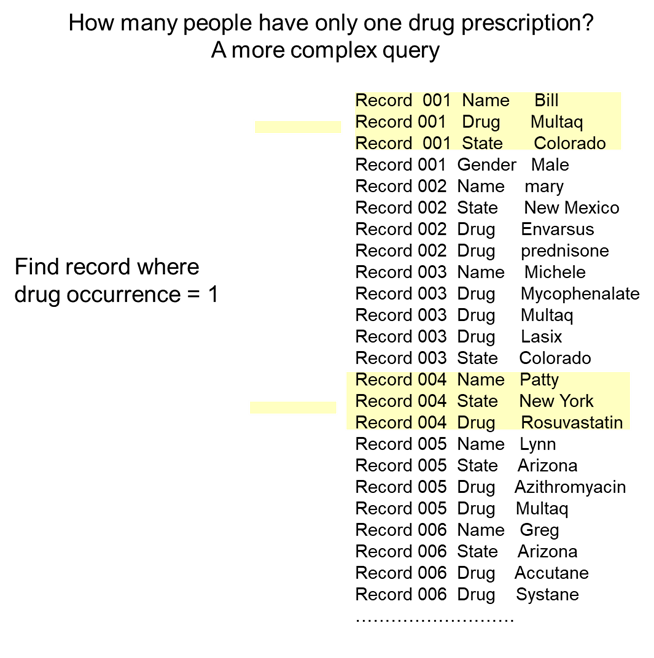
.As an example of a more sophisticated query that can be accommodated by the horizontal structuring of data, consider the query –
How many people have exactly one drug in the data base?
This query is accommodated by looking at all the rows of data for a single record. Once the rows are found, the query then goes into the rows and sees if there is any record of a drug. If there is a record of a drug, then the query determines how many drugs are in the record.
In doing so the data base yields the answer – there are two records of people who have exactly one drug in their medical records.
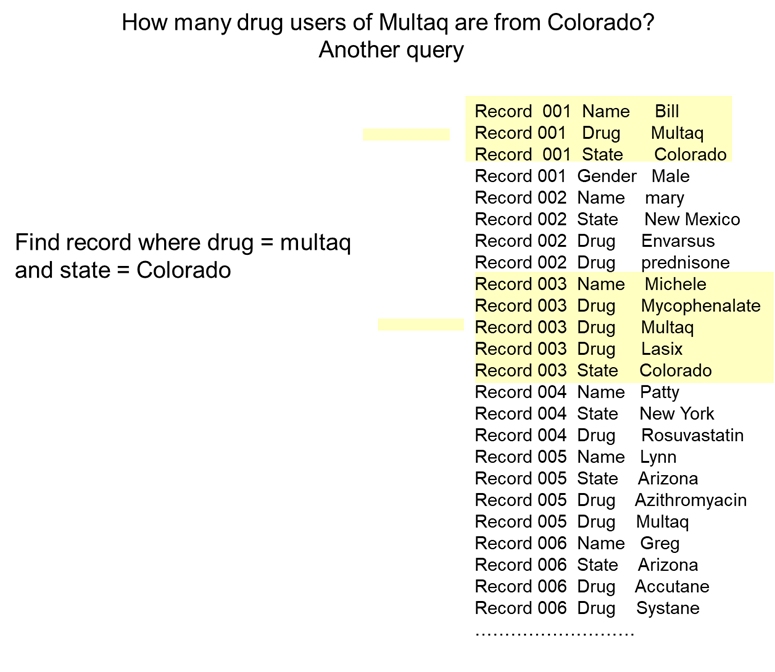
Yet another example of a dynamic structure of data that can be found is one that ask the question –
How many patients are from Colorado and take the drug Multaq?
The query first gathers the rows for a patient. Then the query checks to see if the patient is from Colorado. Next the query sees if the patient takes Multaq.
In the case of the simple data base, there are two patients that meet this criteria.
The simple queries that have been shown illustrate the fact that with a horizontal, dynamic structuring of data, there are many, many structures of data that can be explored. Stated differently, the only relationships of data that cannot be explored using a horizontal, dynamic structuring of data are those relationships that are not mentioned in the text. Otherwise, the relationship can be explored.
By building the data so that data relationships can be created dynamically, the variability and randomness of text can be explored and exploited.

A ROBUST EXAMPLE
As a more elaborate example of the kind of analysis that can be done from a horizontal, dynamic structuring of textual data, consider the following example.
A collection of 10,000 medical records was collected. The doctors notes were written in a free form manner. The patients that were selected for the study had all had some kind of experience with COVID.
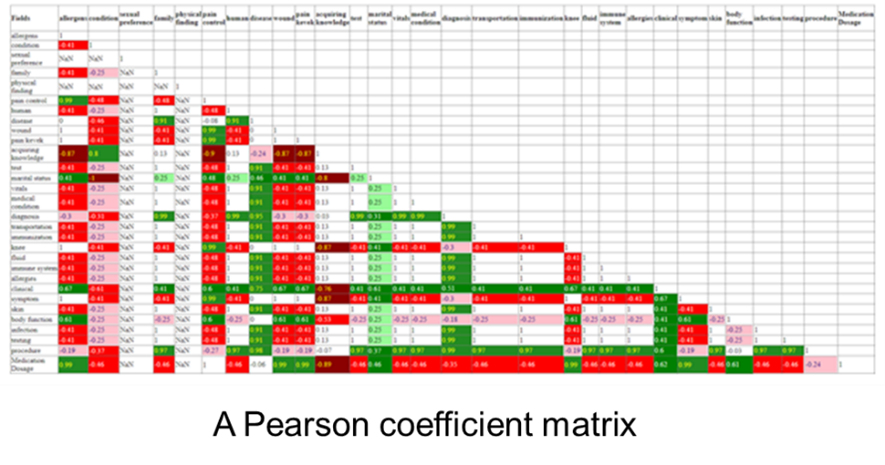
The patients records were read into textual ETL and a horizontal, dynamic data base was produced. Then the records were loaded into a Pearson coefficient matrix.
The Pearson coefficient matrix then compares each word against each other word to see if there is a correlation between the words. A red box that represents the intersection of the words indicates a negative correlation between the words. A green box indicates a positive correlation between the words. A light red box indicates a mildly negative correlation between the words. A light green box indicates a mildly positive correlation between the words.
A white box indicates that no relation has been detected.
The study of COVID patients found some very interesting results. With the Pearson coefficient matrix the relation between COVID and other factors was uncovered –
COVID versus –
Smoking
Alcoholism
Age
Sex
Ethnicity
Other medications ingested
And any other data captured in the medical records.
TIME REQUIRED FOR PROCESSING
The really interesting thing about this analysis is that from the time the 10,000 records were collected that it took about ten minutes time to go from the raw text to the Pearson coefficient matrix.
This short amount of time required for creating an analysis enabled heuristic, analytical processing to be done. The taxonomies used to process the textual data can adjusted to affect the data bases that have been produced. Words could be added to the taxonomy. Words can be deleted. Context could be adjusted. All sorts of adjustments could be made to the taxonomies that were used.
Then the analysis could be rerun.
If the analysis had taken longer – a week, a month, or more – it would have been very difficult to do an iterative analysis of the text.
But an iteration of analysis that takes only ten minutes means that the analyst is able to experiment and see if a better analysis can be done.
CONCLUSION
There are fundamental differences between structured data and text that have a great impact on the way data needs to be structured and analyzed. Structured data requires an ERD data model. Textual data requires an ontology and a set of taxonomies.
Structured data requires a vertical structuring of data. Textual data requires a horizontal arrangement of data.
Both structured data and textual data require context in order to be understood. Structured data has context explicitly defined at the moment of creation. Textual data derives its context for the text in which it appears.
BOOKS
Some books that you may enjoy include –
TURNING TEXT INTO GOLD, by Ranjeet Srivastava and Bill Inmon, Technics Publications
A description of the work required to read raw text and to turn it into a data base
DATA ARCHITECTURE, by Dave Rapien and Bill Inmon, Technics Publications
A description of the work required to build a solid foundation for AI
STONE TO SOLICON – A HISTORY OF TECHNOLOGY AND COMPUTERS, by Roger Wjatley and Bill Inmon
A history of how computing got to be where it is today
Another complete masterpiece Bill. I have sent it out to my very few followers here. LOL!
MASTERING UNSTRUCTURED DATA - DATA MODELS AND DATA STRUCTURES — By W H Inmon
-A data model is to complexity as a compass is to a ship on the sea
-What was once fairly straightforward is anything but straightforward today - yeah, ain't that the truth!
-THE STRUCTURED DATA MODEL
-THE TEXT MODEL
*SO*[!!] Data Base or database? Randall Cooper gives an answer:
'Is there such a word as database (one word)? In dictionaries that are not
very old (e.g., the Webster's New World Second Edition), the word isn't
there. Oddly, in Word for Windows 6.0, the spell checker doesn't reject
the word, but the thesaurus can't find it.
I'd think that data base (two words) is correct. If database is now
correct, can anyone tell me how long that's been true?'
Whereas Lee Rudolph on May 2, 1994, 11:20:23 AM replied:
'I'd think that data base (two words) is correct. If database is now
correct, can anyone tell me how long that's been true?
Correct, I dunno. Current, at least since Knuth's TeXbook
("database" is one of the exceptions he has to explicitly make
for the hyphenation algorithm), what's that, a dozen years or more?'