
METADATA DRIVEN DATA ARCHITECTURE
Never before has data architecture been more important

METADATA DRIVEN ARCHITECTURE
By W H Inmon
Marcel Dybalski
What is the value of “100”?
On a spreadsheet, “100” is innocuous. It sits quietly in a cell. But what does it mean? “100” can be the age of a centenarian. “100” can be a perfect score on an exam. “100” can be the speed at which a vehicle becomes dangerous. Or, “100” can be the price of a stock just before it crashes.
Without context, the number “100” is not data; it is merely digital noise. To transform that number into information, and that information into wisdom, you must have the metadata (the context) surrounding it.
For decades, organizations have treated metadata as an afterthought. It was the “documentation” that developers promised to write after the project went live (a promise rarely kept). But the landscape has shifted. We have moved from an era of data scarcity to an era of data deluge. We are no longer just counting rows in a ledger; we are ingesting customer service emails, analyzing contracts, and scraping web logs.
In this environment, metadata matters more than ever because the distance between the data producer and the data consumer has widened. The analyst in New York does not know the engineer in Bangalore who built the table. Without explicit, rigorous metadata, the analyst is guessing. And in high-stakes business, guessing is a liability.
The Cost of Silence
When metadata is ignored, the modern data platform becomes a liability rather than an asset. This is not merely a technical inconvenience; it is a financial drain.
There are hidden taxes paid by organizations that neglect metadata. One tax is speed. How long does it take a data scientist to find the right dataset? In a metadata-poor environment, the vast majority of an analyst’s time is consumed by searching for data and verifying its origin, leaving very little time for actual analysis.
Another tax is trust. If the Finance department defines “churn” as a cancellation within a specific short window, and the Marketing department defines “churn” as a failure to renew over a longer period, the resulting reports will contradict one another. When executives see conflicting indicators, they stop trusting the data entirely. They revert to gut feeling. The investment in the data architecture is effectively wasted.
But perhaps the greatest cost lies in the inability to process text. Text is fraught with ambiguity. Structured data is rigid; textual data is fluid. If you ignore metadata in unstructured text, you are not just missing context: you are missing the sentiment, the negation, and the intent. You are blind to the customer who says, “I am not happy,” because your system only searched for the word “happy.”
Scope of This Monograph
We will show how properly designed metadata stops being a layer of description and becomes the engine that generates schemas, orchestrates pipelines, enforces policies, and powers impact analysis.
The end state is simple and radical: the human no longer maintains the data architecture. The metadata does.
When that inversion happens, the platform finally becomes trustworthy, fast, and adaptable at enterprise scale.
That is the promise we intend to deliver.
Types of Metadata
To build a data architecture driven by metadata, we must first recognize that metadata is not a monolith. It is a spectrum.
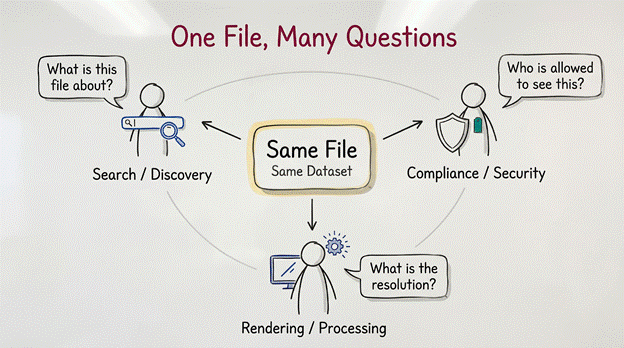
Different questions require different answers. A search engine asks, “What is this file about?” A compliance officer asks, “Who is allowed to see this?” A rendering engine asks, “What is the resolution?”
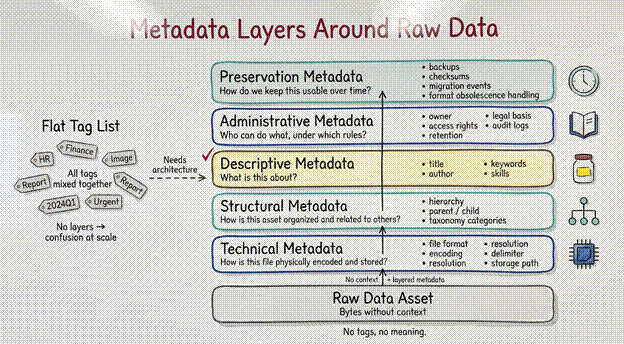
If we attempt to answer all these questions with a single, flat list of tags, the architecture fails. We must instead divide our metadata into five distinct domains, each governing a specific aspect of the data’s lifecycle.
Descriptive Metadata
The Context of Discovery
Descriptive metadata is the label on the jar. It provides the essential attributes, like: title, author, keywords, and summary, that allow an asset to be found within a vast repository. Without descriptive metadata, a file exists, but it is effectively invisible.
Consider a streaming service like Spotify. The platform’s library hosts tens of millions of audio tracks. Descriptive metadata converts a raw audio file into a discoverable piece of art by tagging it with “Composer”, “Duration”, and “Album Art”. This allows a listener to query the interface for “Jazz Instrumentals from 1959”, slicing through the silence to locate a specific sound.
Structural Metadata
The Context of Organization
If descriptive metadata is the label, structural metadata is the skeleton. It defines how data elements are organized, hierarchically arranged, and related to one another.
Data rarely lives in isolation; it lives in compounds. On a website, structural metadata dictates that a specific page is a child of the “Home” page and a sibling of the “About Us” page. It functions like a table of contents in a book, guiding the system (and the user) through the complexity of the whole.
This structure is the domain of Taxonomy. A global retailer cannot function if one region classifies “Mobile Phones” under “Utilities” while another classifies them under “Consumer Electronics.” Structural metadata enforces order upon entropy. It ensures that “T-shirts” always reside beneath “Clothing”, allowing for consistent aggregation across the enterprise. It turns a pile of pages into a coherent narrative.
Administrative Metadata
The Context of Governance
Administrative metadata is the rulebook. It is less concerned with what the data is and more concerned with how the data may be used.
This layer details ownership, access rights, and the legal lifecycle of the asset. It answers critical questions: Who created this record? Who is authorized to modify it? How long must we legally retain it before deletion?
In a regulated environment, administrative metadata is the primary defense against liability. It creates a chain of custody, recording who accessed a file and when. It manages retention schedules, ensuring that sensitive data is purged in compliance with privacy laws (like GDPR or CCPA) or retained for tax purposes. It is the bridge between the data architecture and the legal department.
Technical Metadata
The Context of Mechanics
Technical metadata describes the physics of the digital asset. It captures the file type, encoding standard, storage location, and resolution.
For a data platform to process a file, it must know the technical specifications. An image processing pipeline needs to know if an asset is a JPEG or a PNG, its color profile, and its pixel dimensions to display it correctly. A data engineer needs to know if a dataset is delimited by commas or pipes.
Technical metadata ensures interoperability. It provides the crucial instructions that allow different systems: content management systems, cloud storage buckets, and analytics engines, to handshake and interpret data accurately. Without this layer, a file is not information; it is a meaningless stream of bytes that the machine cannot digest.
Preservation Metadata
The Context of Continuity
Data is fragile. Formats rot; software becomes obsolete. Preservation metadata is the insurance policy against the passage of time.
This type of metadata captures the information required to ensure the long-term usability of an asset. It tracks the history of backups, the checksums for data integrity, and the strategies for migration.
Consider a healthcare organization transitioning from a twenty-year-old legacy system to a modern Electronic Health Record. The clinical data is worthless if it cannot be read by the new system. Preservation metadata guides the porting process, ensuring that patient history survives the technological shift. In industries like legal services and healthcare, where data retention is measured in decades rather than days, preservation metadata is the only thing standing between an archive and a digital graveyard.
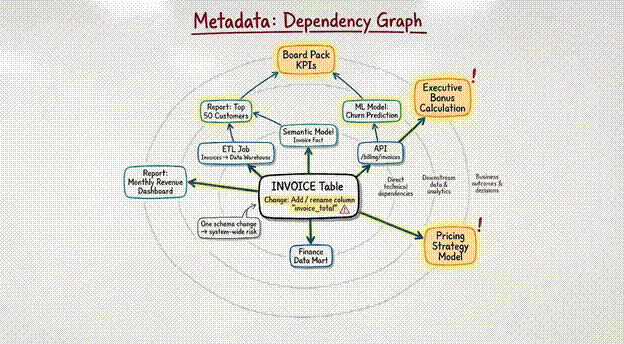
Lineage and Dependency GraphsData is rarely static. It flows. It transforms. It mutates.
A report on the CEO’s desk shows a dip in revenue. Why? To answer that, you must trace the river back to the source. This is Data Lineage.
Most organizations operate in a “black box” environment. Raw data enters a pipeline, magic happens, and a dashboard appears. But what happened inside the box?
Did a filter remove specific transactions?
Was a currency conversion applied using yesterday’s rate or today’s?
Did a join fail, resulting in dropped records?
Metadata must capture the movement. It is not enough to know what the data looks like now. You must know what it looked like then, and exactly which logic altered it.
The Dependency Graph is the result of this metadata. It is the visual representation of fragility. If I change the schema of the INVOICE table, what breaks? Which reports fail? Which machine learning models drift? Without dependency metadata, every schema change is a game of Russian Roulette.
Quality Rules and Thresholds
How do you know if your data is lying to you?
You cannot manually check a billion rows. You rely on trust. But trust in data architecture is not a feeling; it is a metadata construct.
Quality is not a binary state of “good” or “bad”. It is a measurement against a standard. Those standards are metadata. Examples:
● Completeness: “This column must be populated 100% of the time.”
● Validity: “This date cannot be in the future.”
● Consistency: “The sum of the line items must equal the order total.”
These rules should not be buried in the code of an ETL script. They must be elevated to first-class citizens in the metadata repository. By treating quality rules as metadata, you decouple the definition of quality from the execution of the check.
When the metadata says, “This field requires a valid email format” and a row arrives with “N/A”, the system raises a flag. This is the difference between a silent failure (where bad data pollutes decision-making) and a managed exception.
In structured systems, data creates value; metadata makes it trustworthy.

Metadata for Structured Data
There is a comforting illusion found in the grid.
When an analyst looks at a spreadsheet, or a developer looks at a database table, they feel a sense of control. There are rows. There are columns. Every cell holds a value. It looks orderly. It looks defined.
But looking is not understanding.
Just as a single word is often meaningless without a sentence, a number in a database column is meaningless without metadata. What is the number 42? Is it an age? A price? A street number? The answer to the ultimate question of life, the universe, and everything?
Without the metadata wrapper, structured data is merely a pile of digital bricks without a blueprint. It has weight, but it has no purpose. To build an architecture that functions, we must peel back the layers of structure and manage the metadata that holds the grid together.
Classical Constructs: Schemas, Keys, and Relationships
The most fundamental form of metadata for structured data is the schema. It is the physics engine of the database world. It dictates what can exist and how it occupies space.
But simple column names are rarely enough.
Consider the data type. The distinction between an integer and a decimal is not just a technicality; it is a business rule encoded in code. If you store a price as an integer, you have implicitly decided that cents do not matter. That is metadata.
Then there is the concept of identity. The Primary Key.
This is the DNA of a record. It asserts that this specific row is unique and distinct from all others. But what defines that uniqueness? Is it a generated system ID? Is it a social security number? The metadata must capture the nature of the key, not just the value.
And what of the Foreign Key?
Data does not live in isolation. A customer exists in relation to an order. An order exists in relation to a product. The Foreign Key is the metadata construct that binds these entities together. It creates the web of logic. If this relationship is not explicitly defined in the metadata repository, the database is nothing more than a collection of disconnected islands. You cannot navigate from the sale to the salesperson without the bridge.
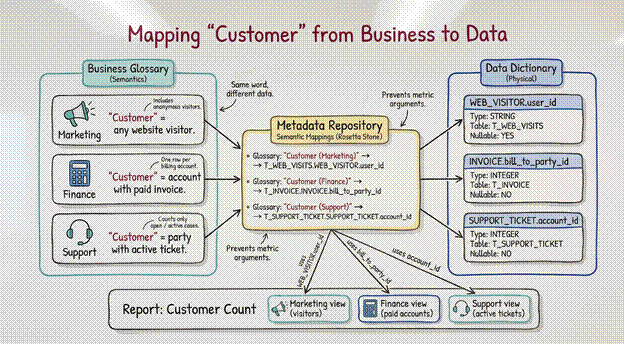
Data Dictionaries and Glossaries
There is a serious gap between what IT builds and what the Business expects. This gap is where projects go to die.
The Data Dictionary is the technical map. It tells the engineer that the column CUST_LTV exists in the T_SALES table, is a FLOAT, and allows NULL values. It is the physical reality.
The Business Glossary is the semantic truth. It defines what “Customer Lifetime Value” actually means. Does it include returned items? Does it calculate based on the last 12 months or the inception of the account?
Here is the obstacle: Homonyms.
Marketing defines a “Customer” as anyone who has visited the website. Finance defines a “Customer” as anyone with a paid invoice. Support defines a “Customer” as anyone with an active ticket.
Three departments. One word. Three different meanings.
If your metadata architecture does not explicitly map the Business Glossary term to the specific Data Dictionary element, you will have executives arguing over reports that show three different totals for the “same” metric. The metadata must serve as the Rosetta Stone, translating the dialect of the database into the language of the boardroom.
Metadata for Textual Data
Like all complex environments, a model greatly helps in the management and understanding of the complex environment. And the world of text is no exception. In many ways the world of language and text is even more complex than the environments that hold and manage data.
The model that is useful for the management of text is the ontology/taxonomy model.
An ontology is a set of taxonomies. The ontology has a general subject area. Typical ontology subject areas might be the airlines industry, the banking industry, the telecommunications industry. Or an ontology might be fore the celebration of holidays, the country of Brazil, or medical research.
There is no limit as to what the theme of an ontology might encompass.
In the case of examining and managing text for business, the ontologies naturally focus on businesses.
The ontology is made up of taxonomies. Each of the taxonomies describes some one aspect of the ontology. For example, the ontology for a bank might contain the taxonomies for such things as –
Credit cards
Loans
Savings
Accounting
Security
And so forth.
Or the ontology for an airline might focus on taxonomies that describe such things as –
Flights
Airports
Gate agents
Reservation systems
Cabin crew
And so forth.
Each taxonomy is focused on its own subject area.
The taxonomy is nothing more than a collection or related words. The taxonomy for credit card might have vocabulary for such things as –
Card holder
PIN number
Credit limit
Credit card number
Cardholder rating
And so forth
The elements of a taxonomy may or may not be connected. For example, there may be a taxonomy called country and another taxonomy called state. The states of Texas, New Mexico and Utah would all relate to the country – USA. But there are no states in Japan, for example.
The world of ontologies and taxonomies is very, very different from the world of data models. Both of the types of models are necessary. But the similarities between the different models ends there.
Central Metadata Model and Repository
If you walk into a library and throw the books on the floor, you still have the content. You have the knowledge. But you do not have a library. You have a pile of paper.
Most data environments today are piles of paper.
The ETL tool knows how data moves. The database knows how data is stored. The BI tool knows how data is visualized. But nothing knows the whole story. To move from a chaotic pile to a functioning architecture, you need a unifying structure. You need a Central Metadata Model.
This section outlines how to organize the invisible layer of your enterprise and the conceptual architecture required to support it.
Core Entities
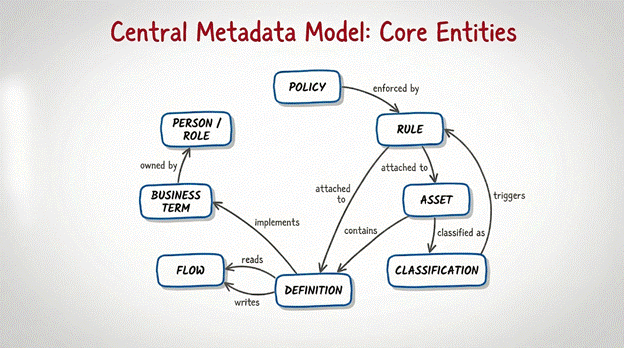
Eight core entities are sufficient to describe and govern the essential semantics, lineage, and control surface of a modern data platform.
1. Asset - the physical or logical thing (table, file, report, model, API, dashboard, document, topic, email, contract)
2. Business Term - the canonical business definition (concepts like “Gross Revenue”, “Active Customer”, “Churn”)
3. Definition - the technical implementation of a business term (formula, JSON path, or NLP entity)
4. Rule - quality, masking, retention, access, tagging, or classification rule
5. Policy - the enforceable business or legal directive (“PII must be masked for non-production environments”)
6. Flow - pipeline, directed acyclic graph (DAG), notebook, or query model (the executable unit of transformation)
7. Person/Role - owner, steward, custodian, consumer
8. Classification - sensitivity level, domain, criticality, lifecycle stage
Other concepts in the data universe are expressed as a relationship between these eight atoms.
A table is an Asset.
A column that calculates Gross Revenue is a Definition linked to the Business Term “Gross Revenue”.
A rule that says “Gross Revenue must never be negative” is attached to that Definition.
A policy that says “Gross Revenue can only be seen by Finance” is attached to the same Definition.
Relationships Between Metadata Objects
The power is not in the entities.
The power is in the directed, versioned graph that connects them.
Every relationship is stored explicitly as a directed edge, and the graph allows traversal in both directions.
Asset → contains → Definition
Definition → implements → Business Term
Business Term → owned by → Person
Flow → reads → Definition → writes → Definition (Flows transform existing Definitions into new Definitions.)
Rule → attached to → Definition/Asset
Policy → enforced by → Rule (Policies exist independently; Rules operationalize them.)
Asset → classified as → PII → triggers → masking Rule (Classifications are descriptive by default; when linked to Rules, they trigger enforcement actions like masking.)
Because these relationships are stored as first-class objects in the graph, the repository can answer questions that previously required weeks of tribal archaeology:
“Who owns the definition of Churn?”
“Show me every dashboard that would return incorrect results if we change the revenue Definition from gross to net.”
“Which pipelines will be affected if new regulations force us to delete records older than seven years?”
The graph answers almost instantly.
Versioning and History: The Fourth Dimension
History is slippery.
What was the definition of “Sales Territories” in 2019?
It is likely different from the definition of “Sales Territories” today.
If you run a report on 2019 data using today’s definition, you will get the wrong answer. You will judge the past by the rules of the present.
Therefore, the Central Metadata Repository must be versioned.
It must capture the history of the metadata itself. It must be able to say:
“From January 1, 2018 to December 31, 2020, ‘Revenue’ included shipping costs. Starting January 1, 2021, ‘Revenue’ excludes shipping costs”.
Without versioning, the analyst is blind to the changes of the past. They see the data, but they do not possess the context of time.
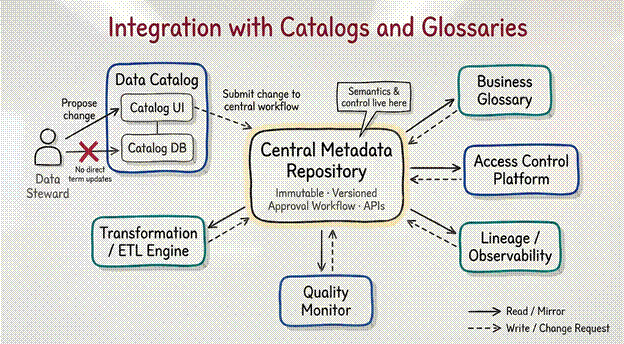
Integration with Catalogs and Glossaries
The central model does not replace the commercial catalogs, quality monitors, or transformation engines.
It colonizes them.
Every external tool becomes a thin presentation layer sitting on top of the central graph.
They are allowed to exist, but only as read-only mirrors.
When a data steward updates a business term in a catalog interface, the change is immediately rejected unless it is pushed through the central repository’s approval workflow.
Once approved in the center, the new version is pushed out to every tool simultaneously.
This ends the religious wars about which tool is the source of truth.
There is only one source.
Everything else is a consumer.
The same principle applies to transformation frameworks, quality testing suites, and access control platforms.
They all read from and write to the same immutable graph via APIs.
When this repository exists, metadata finally stops being documentation.
It becomes the living, executable nervous system of the enterprise.
And the architect’s job changes forever: from designing pipelines to designing the graph that builds the pipelines.
Driving Architecture from Metadata
In the past, metadata was always the final step. Engineers built the pipelines, created the tables, and wrote the code. Then, if they had time, they wrote down what they did.
This approach is backwards. It means the documentation is always chasing reality.
In a modern platform, we flip the script. Metadata comes first. It does not just describe the architecture; it generates the architecture.
This represents the shift from Passive Metadata (a catalog you look at) to Active Metadata (a configuration the system reads). By treating metadata as the source code of the platform, we eliminate manual work, reduce human error, and ensure everything stays consistent and up to date.
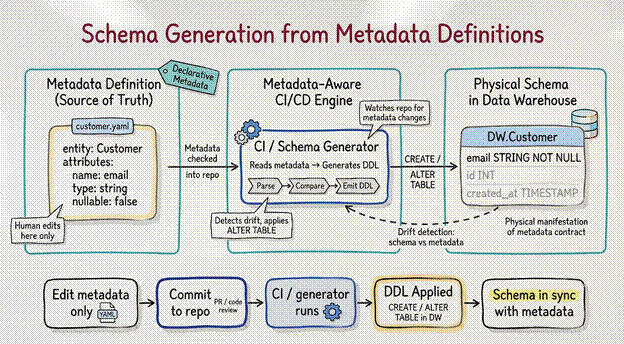
Schema Generation from Metadata Definitions
Writing CREATE TABLE statements by hand is a liability. It invites inconsistency. One engineer defines a timestamp as DATETIME; another defines it as TIMESTAMP_NTZ. One names a customer identifier cust_id; another names it customerId.
When architecture is driven by metadata, the engineer does not write SQL. They write a declarative definition (often in YAML or JSON) that describes the entity.
For example, the metadata definition states:
● Entity: Customer
● Attribute: Email
● Type: String
● Nullable: False
A continuous integration process reads this definition and automatically executes the precise DDL commands required to create or update the table in the target data warehouse. If the metadata definition changes, the system detects the drift and automatically applies the necessary ALTER TABLE command. The database schema becomes a physical manifestation of the metadata contract.
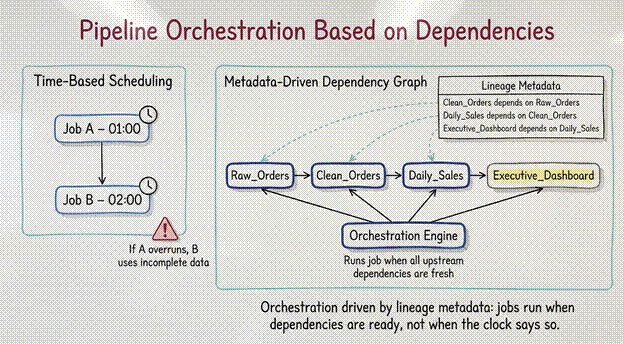
Pipeline Orchestration Based on Dependencies
The most brittle architectures rely on time-based scheduling. Job A runs at 01:00. Job B runs at 02:00. If Job A takes 65 minutes, Job B processes incomplete data.
Metadata-driven orchestration rejects the clock in favor of the graph.
Because metadata captures lineage (the knowledge that Table B depends on Table A) the orchestration engine can dynamically generate the execution path. The system does not run a job because it is 02:00; it runs the job because the metadata signals that the upstream dependencies have successfully refreshed.
This approach allows for dynamic backfilling. If a business rule changes for a metric calculated three steps upstream, the metadata engine identifies every downstream dependency. It can automatically trigger a re-computation of historical data for exactly those tables affected, without human intervention to map out the dependency tree.
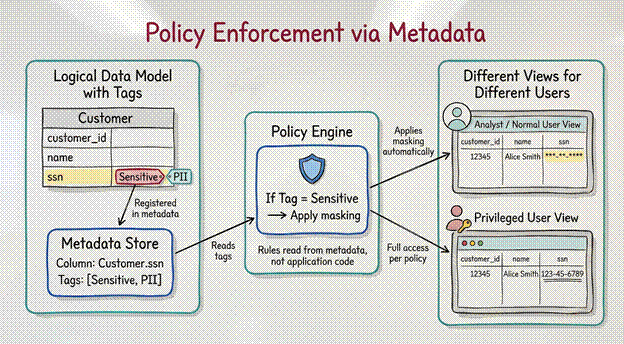
Policy Enforcement via Metadata
You cannot trust human memory for security.
“Always hide the Social Security Number”. This is a simple rule. But developers get tired. They forget. Eventually, someone will make a mistake and show the number.
In a metadata-driven system, we do not rely on memory. We use tags.
1. Tagging: A manager puts a tag called Sensitive on the Social Security Number in the system.
2. Enforcement: The system sees the tag.
3. Action: The system automatically locks that column.
Now, when a normal user looks at the data, they see ***-**-****. The developer did not have to write code to hide it. The metadata did it automatically. The rule is in the system, not in the person’s head.
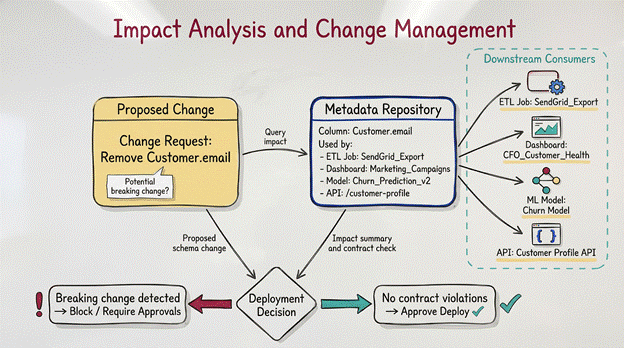
Impact Analysis and Change Management
The most terrifying button in data engineering is “Deploy”.
In a complex environment, changing the data type of a single column can break a dashboard used by the CFO, fail three downstream ETL jobs, and corrupt a machine learning model. In a manual architecture, these dependencies are guessed at.
Metadata provides a “blast radius” calculation. Before a change is applied, the system queries the metadata repository: “If I modify this column, who consumes it?”
The architecture can then block a deployment that violates a contract (e.g., removing a column used by a production API) or automatically notify the owners of the downstream dashboards that a change is incoming.
Closing word
We began this monograph with a single, innocuous number: “100”.
Sitting in a cell without context, it was meaningless. It could have been the age of a grandmother, the speed of a reckless driver, or the price of a stock. We end this journey not just with a definition of that number, but with a blueprint for an architecture that systematically guarantees meaning across the entire enterprise.
The transition to a metadata-driven data architecture is not merely a technical upgrade; it is an evolution of organizational maturity.
Measuring Success
Do not measure success by the number of columns defined or the number of users logged into a catalog. Those are vanity metrics. True success is measured in velocity and trust.
● Velocity: How long does it take a new analyst to encounter the number “100” and know exactly what it measures? In a traditional setup, this takes days of asking around. In a metadata-driven setup, it takes seconds.
● Trust: When the CFO asks if that “100” is accurate, can you provide the lineage map instantly, or do you need a week to audit the SQL scripts?
Future Directions
We are standing at the edge of the Generative AI era. Large Language Models and corporate AI agents are hungry for data. But these models are incredibly sensitive to the context crisis. If you feed an AI the number “100” without metadata, it guesses. It hallucinates.
In the coming years, metadata will be the bridge between your raw data and your AI. It will be the guardrail that ensures your automated agents understand that “100” is a percentage, not a currency, preventing costly errors.
The era of managing data by brute force is over. The era of managing data through metadata has arrived. Provide the context, and the wisdom will follow.
Never again let “100” stand alone.
About the Authors
W.H. Inmon is widely recognized as the father of the data warehouse and was named as one of the ten people who most influenced the first 40 years of the computer industry. Bill has sold over 1,500,000 books in his life.
Marcel Dybalski is a consultant and engineer specializing in AI and data platforms. For almost a decade, Marcel has helped organizations design and implement platforms with a strong emphasis on solid data architecture and management, always keeping the broader enterprise landscape and long-term business goals in mind.
 | A guest post by
|
Exactly my point too!
Go metadata! For a deep dive, see https://www.amazon.com/dp/B0GNM1LVN1