
UNDERSTANDING THE BUSINESS LANGUAGE MODEL - BLM
UNDERSTANDING THE BUSINESS LANGUAGE MODEL
By W H Inmon
In 2002 the question came up – why are corporations using only 5% of their data for making 95% of their decisions? At that time only structured data was being used in the decision making process in the corporation and structured data represented only a small fraction of the data found in the corporation.
Out of intellectual curiosity I sat down and started to deeply ponder this question in 2002. The musings quickly led to the fact that text was not useful for computer processing given the state of computer technology at that time. The unstructured nature of text did not fit well with computing. Computing was designed for highly structured data, not rag tag, amorphous text. In addition, textual data had it own unique sets of complications that had to be overcome before it was useful for corporate decision making.
TEXT AND DECISION MAKING IN THE CORPORATION
This line of thinking- asking why wasn’t text a part of the corporate decision making process - quickly led to the recognition of the need for a language model. If text was ever going to be unraveled and used in corporate decision making, the unravelling of text had to be done with a language model. In 2002 there were no guidelines as to what constituted a language model. In fact, in 2002 no one had ever heard of a language model.
THE LANGUAGE MODEL
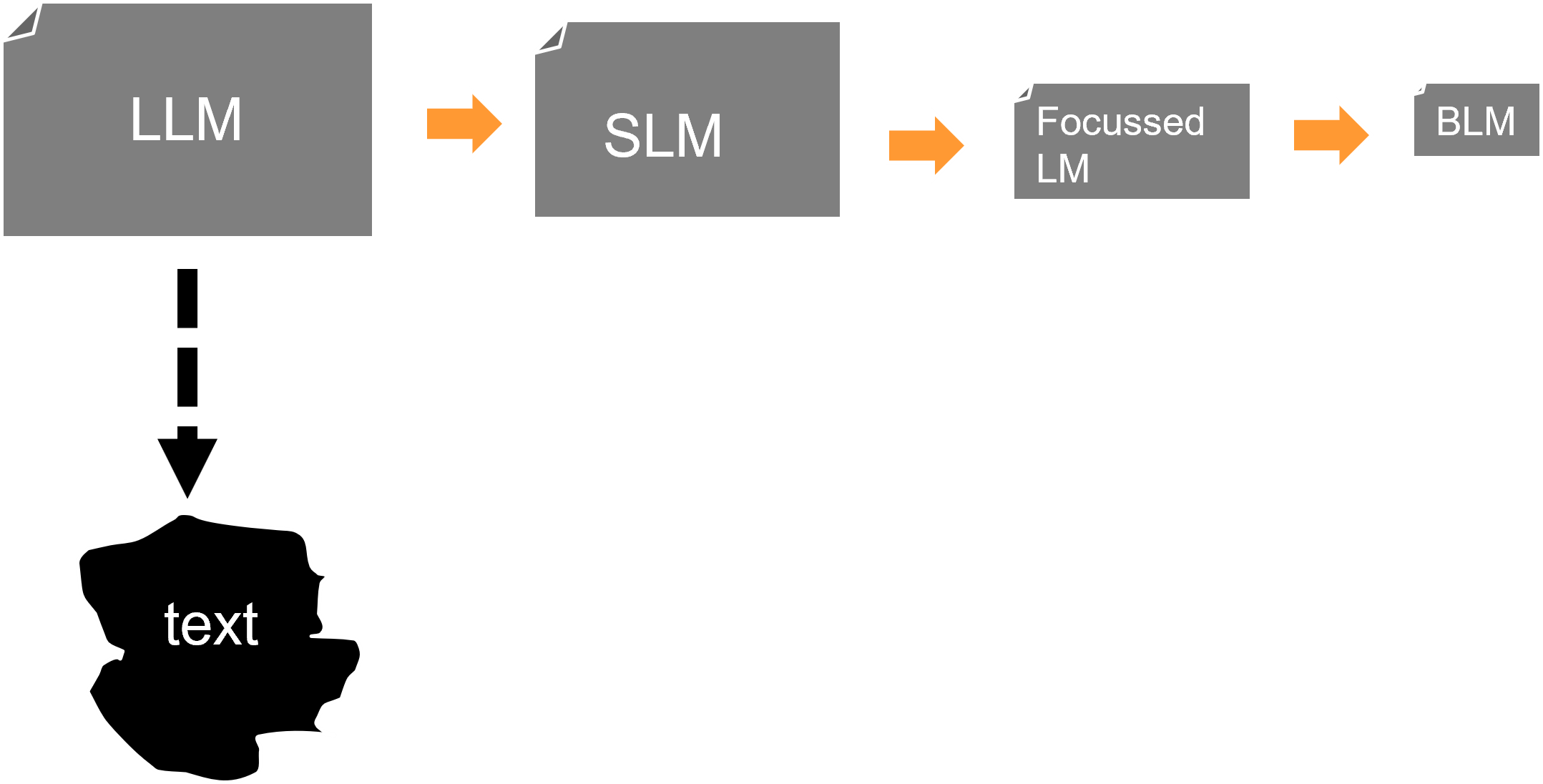
The first attempt that I made in 2002 at a language model was to build what was construed as a full, encompassing language model. A full encompassing language model would encompass a model for all language. Today, that attempt at an early language model of 2002 would be called an LLM, although in 2002 no one had ever spoken those words. It was quickly discovered that an LLM wasn’t what was needed.
There were a host of problems with the building of the early version of the LLM –
The LLM was very, very large, for all purposes infinite in size
The language that was contained in the LLM was very complex
Only a small fraction of the words found in an LLM were needed in order to study a given piece of raw text
The LLM was constantly changing. Even if you could build one, the LLM would have to be changed as soon as it was finished. You just never finished building the LLM
In short, it was a fool’s game to try to build a true LLM.
THE SLM – SMALL LANGUAGE MODEL
So sights were reset. Maybe a smaller version of an LLM would work. Maybe a smaller version of the LLM – a small language model – SLM - would be more practical.
It is true that the scope of the SLM is smaller than the scope of the LLM. That fact alone makes the SLM a much better, attainable goal. But the SLM proved to be only slightly easier to work with and build than the LLM. The SLM still had many of the drawbacks of the LLM.
THE FOCUSED LANGUAGE MODEL
A third attempt at building the needed language model was the focused language model. The focused language model had the advantage of being finite in size and being of a size that was manageable. But the focused language model still was a hassle to build and maintain. In many cases, building the focused language model took more effort than trying to actually use the focused language model itself.
THE BLM – BUSINESS LANGUAGE MODEL
The fourth step in the evolution of the language model was that of the building of the business language model – the BLM. While a significant effort was required in the building of the business language model, the BLM could still be built. The BLM was not infinite in size. The interesting thing was that once the BLM was built for an industry, the BLM could be applied to all companies engaged in that industry. A BLM for banking applied to Citicorp, Bank of America, Wells Fargo and JP Morgan. A BLM for fast food applied to Burger King, McDonalds, Subway and Chick Fil E. There was no need for the building of a separate BLM for all companies involved in an industry. Generic BLM’s sufficed very nicely because they were finite in size and were generic in scope.
The progression of language modelling looked like -
THE GENERIC LANGUAGE COMPONENT
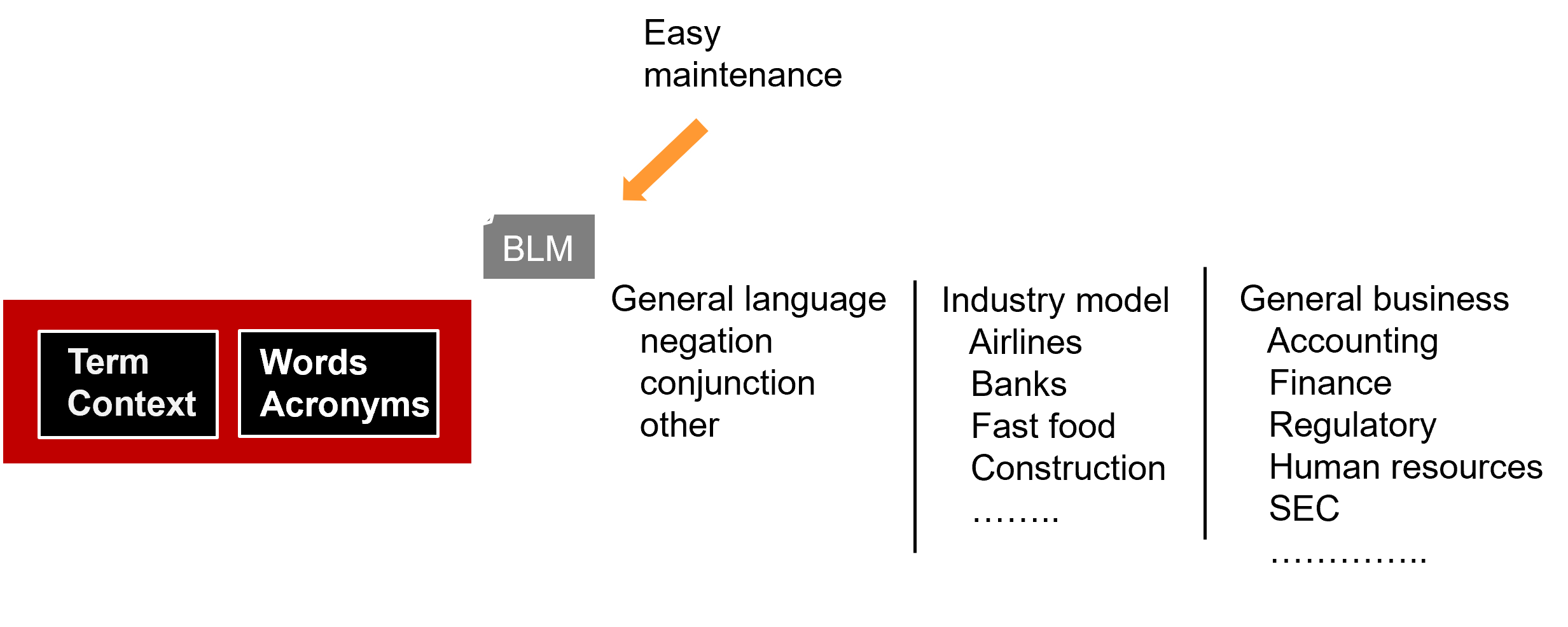
The BLM had several unique components. The first component was the generic language model. The generic language model applied to the vocabulary that was used in everyday speech regardless of who was speaking. This part of the model applied to generic language terms such as negation and conjunctions. This part of the language model was generic to all users of language models. The generic language model was tiny in comparison to the rest of the language model.
THE INDUSTRY SPECIFIC COMPONENT
The second component of the BLM was the industry specific component. The industry specific component of the BLM contained vocabulary specific to the industry that was being disambiguated. Banks had credit terms, loan terms and savings terms. Fast food had menu items, service terms and ambience terms. Real estate had listing terms, appraisal terms, and contract terms. Airlines had reservations systems, upgrade programs, flights and baggage handling.
There may be some small overlap between one industry language model and another industry language model. But the overlap was not much.
THE GENERAL BUSINESS TERMS
The third component of the BLM was the general business terms that any large business would have. These terms included accounting terms, finance terms, legal terms, and so forth.
ACRONYMS
In addition to actual vocabulary, acronyms needed to be included in the language model as well.
CONTEXT
Another important component of the BLM was the need for context as well as the term itself. Each word found in the BLM needs to have both the word and the context of the word identified as well. On occasion a word would have more than one context. Consider the word “fire”. The word “fire” can mean a conflagration, the pulling of the trigger of a gun, or the dismissal of an employee. The word fire would appear three times in the BLM, where each entry of “fire” into the BLM would have it’s own unique context identified.
MAINTENANCE OF THE BLM
Another feature of the BLM is that the BLM needed to be easily and efficiently maintained. The BLM is generic to all companies in the same line of business. Each business will have vocabulary that is understood only within the walls of the company. The generic BLM needs to be able to accommodate this outlying words and vocabulary for each corporation employing the BLM.
LANGUAGE MODEL EVOLUTION
The progression – the evolution of language models - that has been described is the one I went through starting in 2002. What is amazing is that today the world is going through the same evolution – on a much grander scale. What is even more amazing is that the world insists on going through the evolution of language models on a trial and error basis. The industrial progression of language models that is occurring today is the same progression that I went through years ago. It is painful and slow to use trial and error as the teacher. It is also not smart. But dumb people learn the hard way.
The world insists on not looking around and seeing what has been done and building on paths that have already been trod. The irony is that the world will end up – courtesy of the pain and waste of trial and error - where we were at fully two decades ago.
BLM’s already are built and have been built for a long time now, The world insists on subjecting itself to pain that is unnecessary and hugely wasteful by not learning from that that has already been done.
THE ANATOMY OF THE BLM
At the heart of applying ChatGPT to business is the business language model – the BLM.
So what does a BLM look like? How could you tell a BLM from a baseball? From Tom Cruise? From the Mississippi river?
The BLM has a distinctive shape and content. At a high level the contents of the BLM are -
SIMPLE INTERNAL STRUCTURE
The physical content of the BLM is simple. It consists of a word or acronym related to context and in some cases to a second level of context or an identification of the library where the word and its context can be found..
A simple example of the physical structure of a BLM looks like –
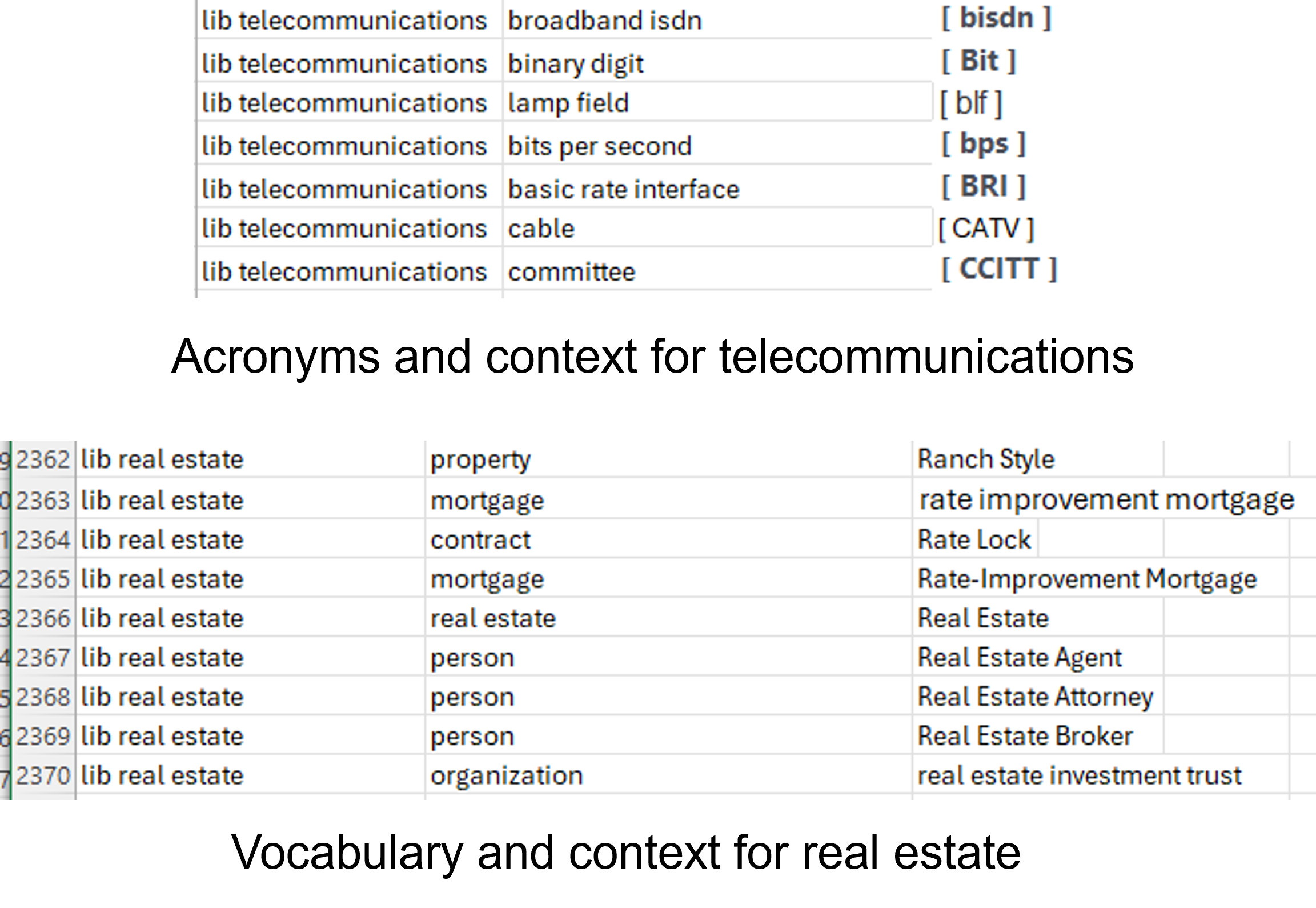
The top snippet shows acronyms for the telecommunications industry along with the context of the acronym. The acronym for cable TV would be CATV. The bottom snippet shows vocabulary for the real estate industry along with the context of each word. One type of property is ranch style, for example.
To the left of the context of the word is the library which contains the word and its context.
The simplicity of the physical manifestation of the BLM belies the complexity of the structure of the content. Even though the physical structure is simple and straightforward, the types of vocabulary – the components of the BLM - found in the BLM is anything but simple and straightforward.
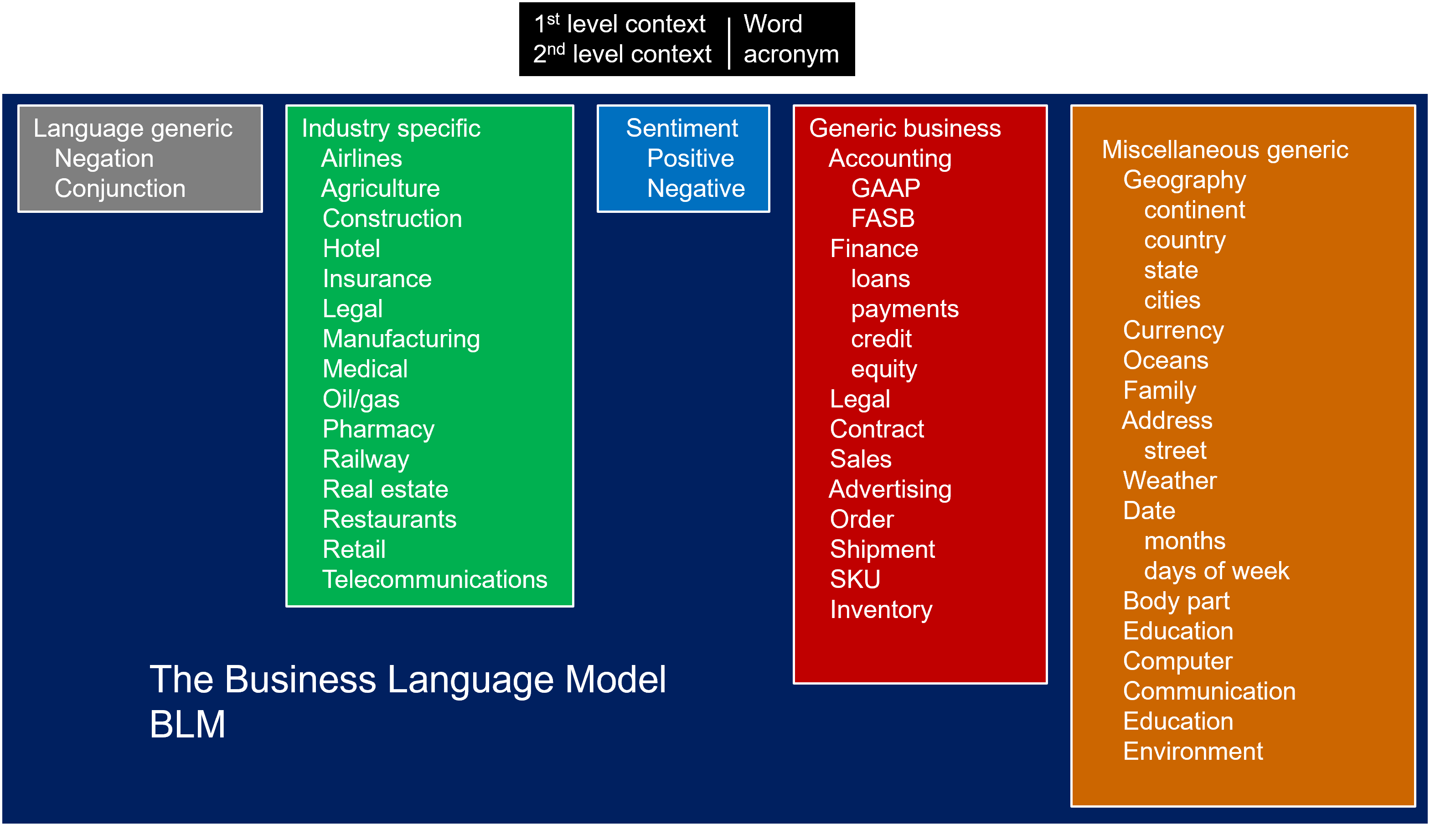
The structure of the contents shows different categories or components of vocabulary.
At the physical level there really are only three components to the BLM. Those physical contents are –
The library the word appears in
The context of the word
The word or phrase itself or the acronym representing the word or phrase
GENERIC LANGUAGE
The smallest and simplest category of vocabulary found in the BLM is that of generic language. Generic language includes negations and conjunctions – “no”, “hardly”, “never”, “and”, “but”, “or” and so forth. The generic vocabulary applies across all industries. The generic language component of the BLM is tiny compared to the remainder of the BLM. The generic language is also static. Rarely is there a new word needed to be added to the generic language component.
INDUSTRY SPECIFIC TERMS
The second category of vocabulary found in the BLM is the category of industry specific terms. Banking will have terms such as “credit card”, “loan”, “savings account”, and so forth. Real estate will have terms such as “sold”, “asking price”, “earnest money”, and so forth. There is some but not much overlap of the vocabularies across different industries.
The industry specific component of the BLM is designed to be combined with the general business component in the final rendering of the BLM.
GENERAL BUSINESS TERMS
The third category of vocabulary found in the BLM is the generic business terms. These are terms that will apply to any large business, regardless of the business they are in. the generic business terms include such categories as accounting, finance, legal, and so forth. Typical terms might be “deadline”, “filing”, “stockholder”, “regulation”, “organization chart”, and “taxation”.
The generic category of vocabulary applies equally to any large business.
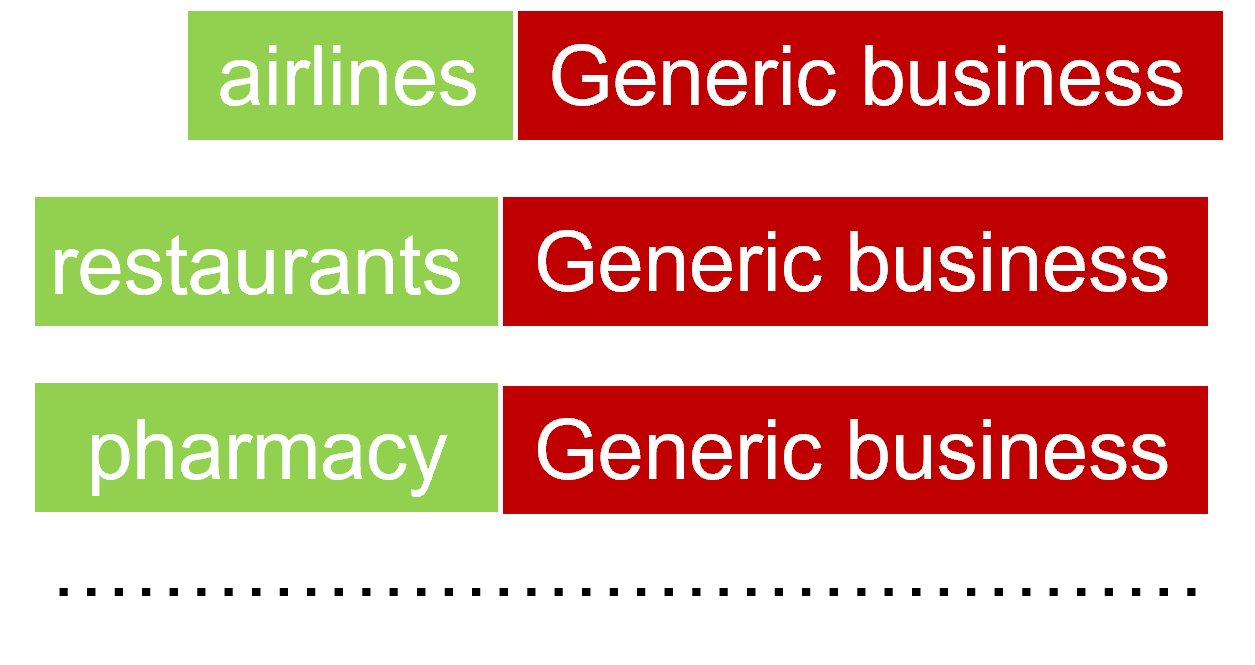
COMBINING INDUSTRY SPECIFIC AND GEBERAL BUSINESS TERMS
The industry specific terms are married to the general business terms to form a unique language model for each industry. The figure shows that airlines have been combined with the general language component. Restaurants have been combined with the same general language component. Pharmacy vocabulary has been combined with the general language component as well.
SENTIMENT ANALYSIS
Another category of words is sentiment analysis. Sentiment analysis contains both positive and negative sentiment. Typical sentiment vocabulary includes words such as “like”, “love”, “disappointed”, “hate”, “waited in line” and so forth.
MISCELLANEOUS TERMS
The final category of words is the miscellaneous category. The miscellaneous category contains words used in everyday conversation, such as “Tuesday”, “April”, “Brazil”, “St Louis”, and so forth. Dates, geography, family, time of day, addresses, maps and other are found in the miscellaneous category of vocabulary.
RARELY USED TERMS
As a matter of principle, the BLM contains only the words commonly used in speech and in commerce. The BLM probably would not contain such rarely used words as “crwth”, “accismus”, “cachinnate”, “agelast”, and so forth. The probability of encountering rarely seen words is such that it does not make sense to include these rarely used words.
But because rarely used words are sometimes needed to be included into the BLM, the BLM must be able to include such words easily and expeditiously if needed. In other words, the infrastructure needed to build the BLM must be agile and aware of the need for simplicity and speed in the construction and maintenance of the BLM.
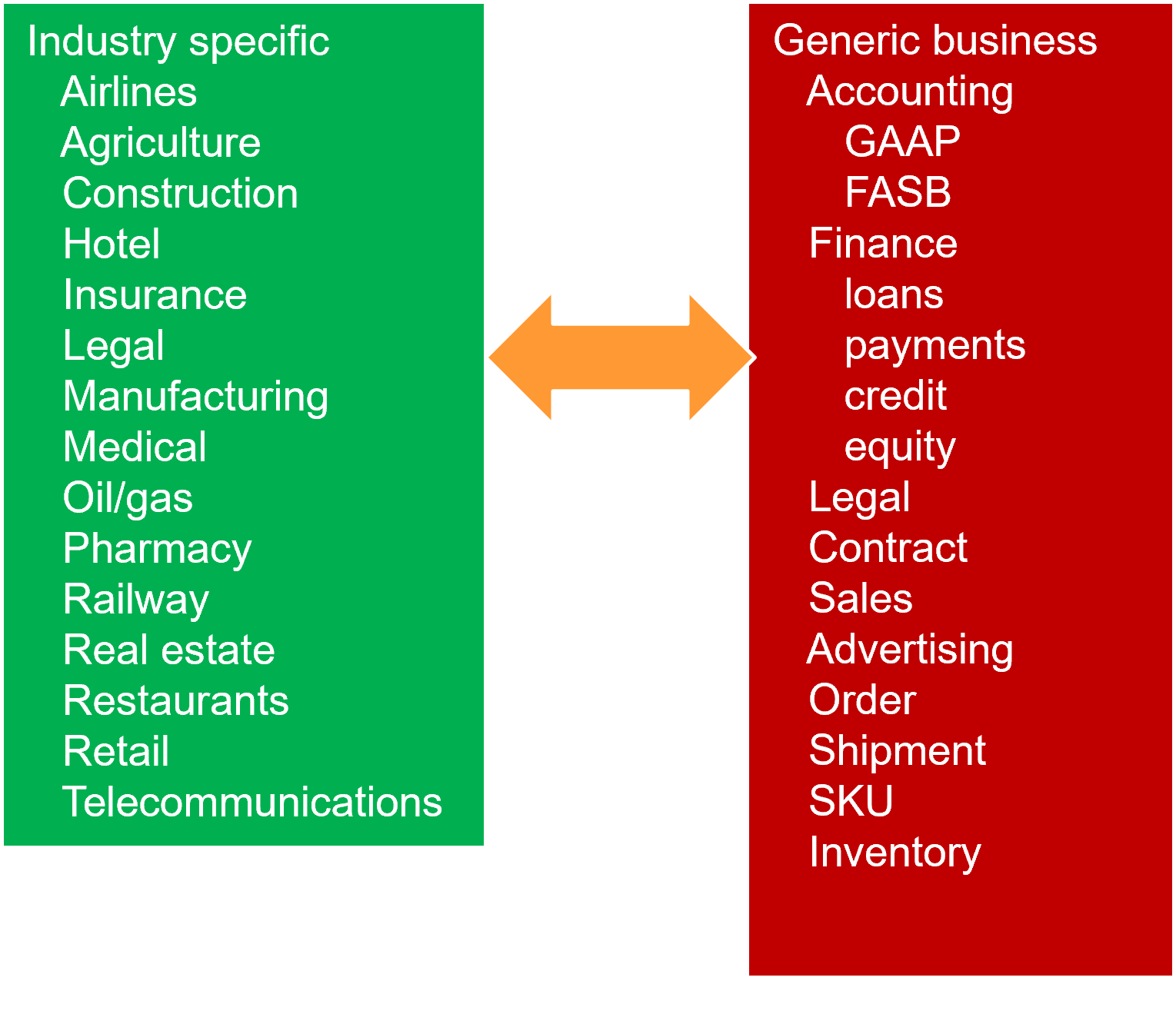
COMBINING THE COMPONENTS
The different kinds of vocabulary are combined in order to create a BLM. The figure shows the different components of the BLM’s that can be created.
In general, the BLM contains all of these components. However, one rare occasion, one or more of the components can be omitted.
This then is what the anatomy of the BLM looks like.
ONGOING MAINTENANCE
One aspect of building and planning for a BLM is the consideration of the ongoing maintenance of the BLM. In general BLM do not need much maintenance and care. But there are circumstances where the BLM does need care.
Those circumstances are –
When language changes. Language changes glacially, but language does change over time
When business changes. Business is constantly changing. Most business changes incrementally and fairly slowly. But business is constantly changing and those business changes need to be reflected in the BLM
When new arenas of the business need to be included in the BLM. This type of change occurs fairly frequently
In any case, it needs to be recognized that the BLM does require periodic update and maintenance.

Of interest is the fact that not all types of vocabulary are necessarily needed to be included in the BLM. For example, if no sentiment analysis is to be done it is not necessary to include sentiment vocabulary in the BLM.
OTHER LANGUAGES
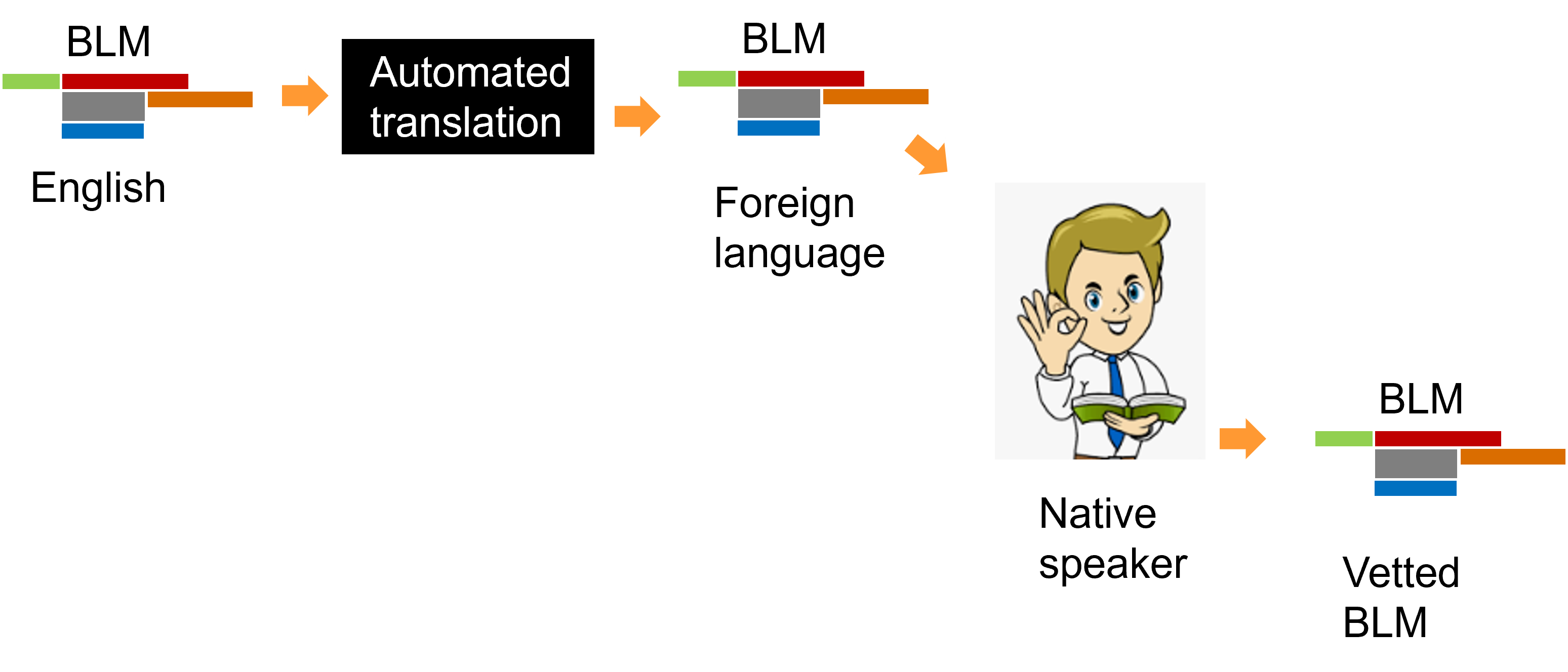
It is of interest to note that BLM’s can be translated into other languages quite easily. The English version of the BLM is translated using an automated translator, as found on the Internet. The translated version is then vetted by a native language speaker. The final result is a BLM that is functional and usable in a foreign language.
It is possible but not advised to not vet the translated version with a native speaker. However, when that is done there is the risk that vocabulary that is translated automatically has not been translated correctly.
USING THE BLM
Once you have built the BLM, what can it be used for? The answer is – the BLM has many uses.
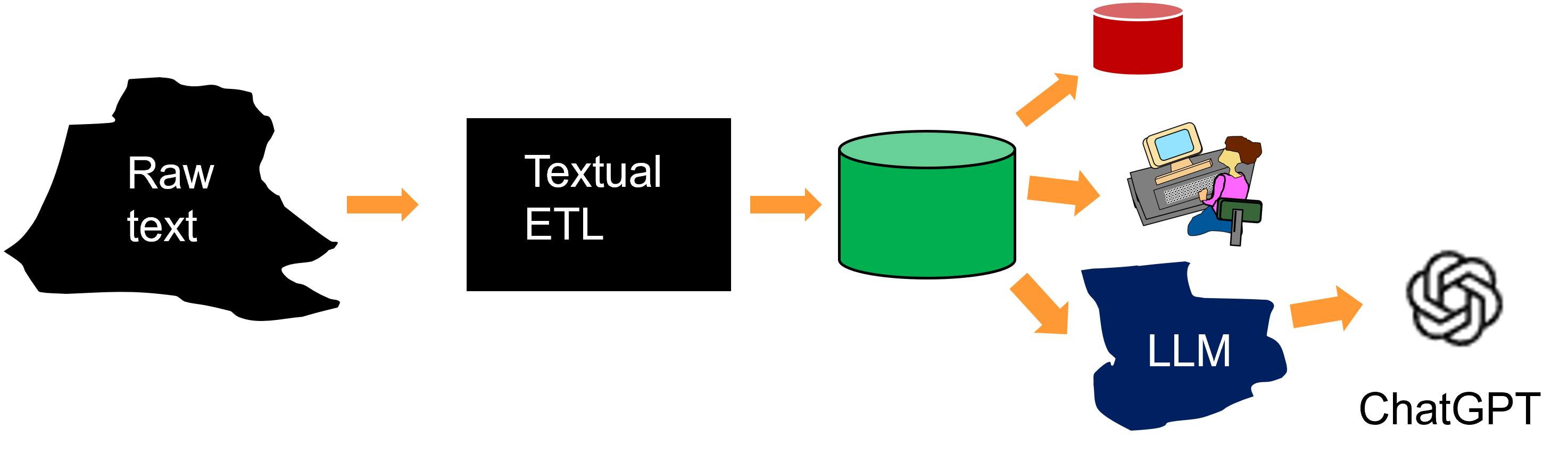
One typical use is to apply the BLM to textual ETL. The BLM is input into textual ETL and is used to examine raw text and pull out words found in raw text that are useful for further analysis.
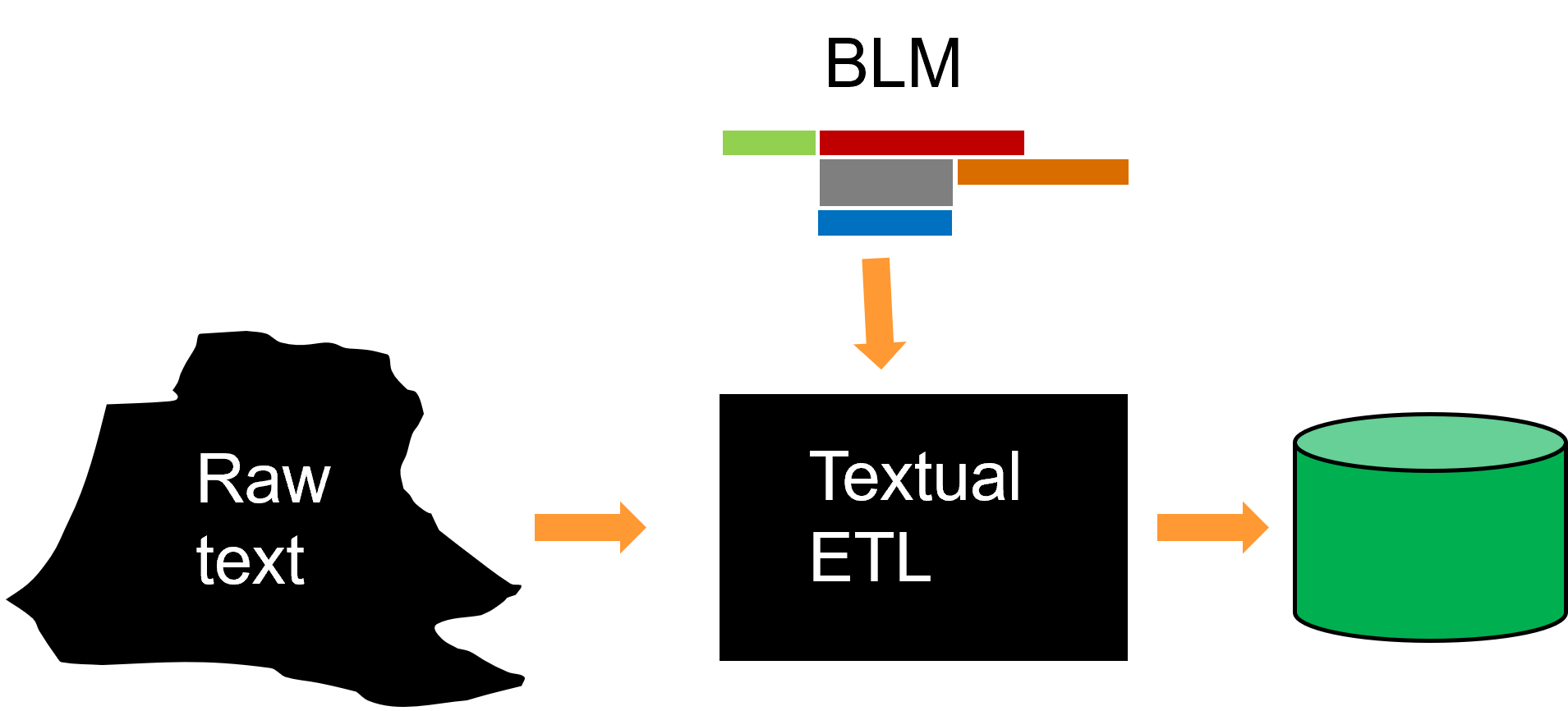
The BLM interacts with textual ETL in the identification and the contextualization of raw text. Raw text is read and the BLM is used to identify the words that have been read and those words are selected for inclusion in the output data base. In addition, the words that have been selected are contextualized.
THE BLM IN ACTION
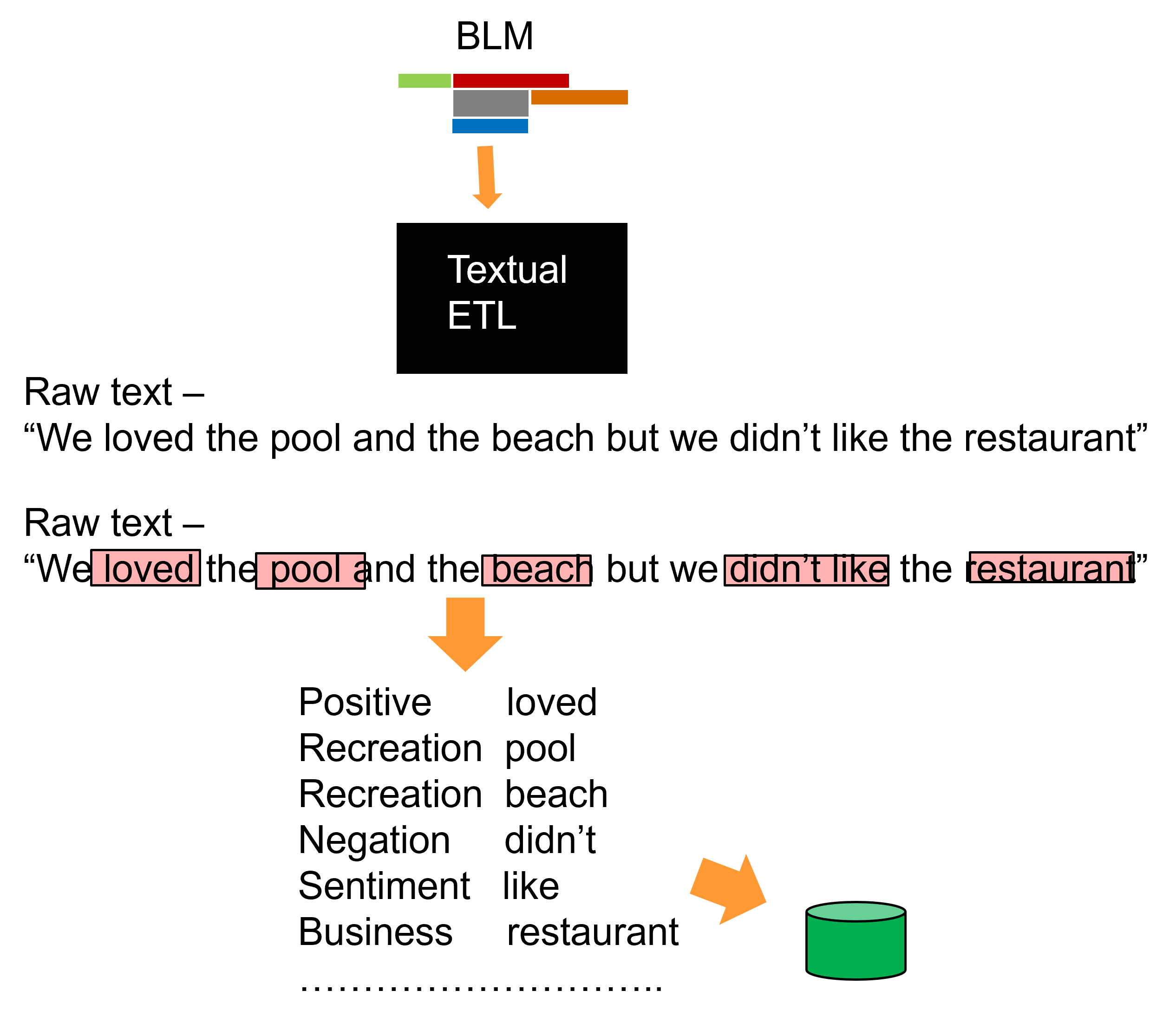
The following figure shows how the BLM is used by textual ETL.
The raw text is read and the BLM is used to pick out the words that are specified by the BLM. The BLM incorporates only the words that are of interest to the analyst.
The words are selected from the raw text and the context of the words are selected from the BLM. The words and their context are then placed into a data base.
In addition to the selection of the words and their context, textual ETL also selects the name of the document the words originated from and the location of the word in the document. By selecting the source of the word, it is ensured that the integrity of the document is preserved. If there ever is any doubt as to the origin of the word, the word can always be traced back to its source.
THE TEXTUAL BASED DATA BASE
Once the words are selected and contextualized, they are placed in a data base. In addition to the contextualized word, the source of the word is identified in the output data base.
What can be done with the resulting data base? The answer is – a lot.
There are lots of advantages to the creation of the data base. But the biggest advantage is that with the text in the form of a data base, an unlimited amount of text can be accommodated. As long as text is in the form of text, it must be processed manually. A human being can read and absorb only so much data. But a computer is able to read and absorb an unlimited amount of data.
There are other advantages to the creation of a data base. But the ability to scale to infinity has to be the largest advantage of turning text into a data base.
BLENDING WITH OTHER CORPORATE DATA
One thing that can be done with the resulting textual based data base is that the textual data can be mixed and blended with other corporate data. This capability opens up the door to all sorts of analysis that otherwise would never have been possible.
Another use of the textual based data base that has been produced is to do analysis directly on that data. All sorts of analysis can be done –
Sentiment analysis
Corelative analysis
Cumulative analysis
And so forth.
LOADING CHATGPT
Another important use of the textual data base that has been produced is the filtering of data for loading into the LLM that supports ChatGPT.
There are then a myriad of reasons for the creation of the BLM. In many ways the BLM becomes the key to bridging the gap between technology and business. The BLM opens up text for analytical processing by the corporation and ChatGPT.
Books you may enjoy –
TURNING TEXT INTO GOLD, Technics Publications, Sedona, Arizona
DATA ARCHITECTURE – BUILDING THE FOUNDATION, Technics Publications, Sedona, Arizona
THE TEXTUAL WAREHOUSE, Technics Publications, Sedona, Arizona
STONE TO SILICON: THE HISTORY OF TECHNOLOGY AND COMPUTING, Technics Publications, Sedona, Arizona
Hi,
Bill really needs recognition for his work. He was on the spot decades ago.
Nowadays I belive AI can produce the BLM (and much more) easily if you feed it with business spesific data.
Hi Bill,
This is a brilliant and much-needed perspective in the AI space. The concept of a Business Language Model tailored to specific industries strikes a great balance between practicality and innovation. It’s clear that focusing on industry-relevant vocabulary and business logic makes AI more accessible and effective for enterprises.
That said, I believe the success of any language model, BLM included, relies on the foundational data quality. Without strong data governance, rigorous labeling, and thoroughly managed metadata, even the most well-designed model risks falling short in scalability and reliability. Your BLM concept perfectly complements these foundational efforts by offering an adaptable, industry-focused framework built on top of that strong data foundation.
Looking forward to seeing how this evolves and its impact across industries!
Best,